How can You Build It You Run It be applied to 10+ teams and applications without an overwhelming support cost? How can operability incentives be preserved for so many teams?
This is part of the Who Runs It series.
Introduction
You Build It You Run It at scale means 10+ Delivery teams are responsible for their own deployments and production support. It is the You Build It You Run It approach, applied to multiple teams and multiple applications.
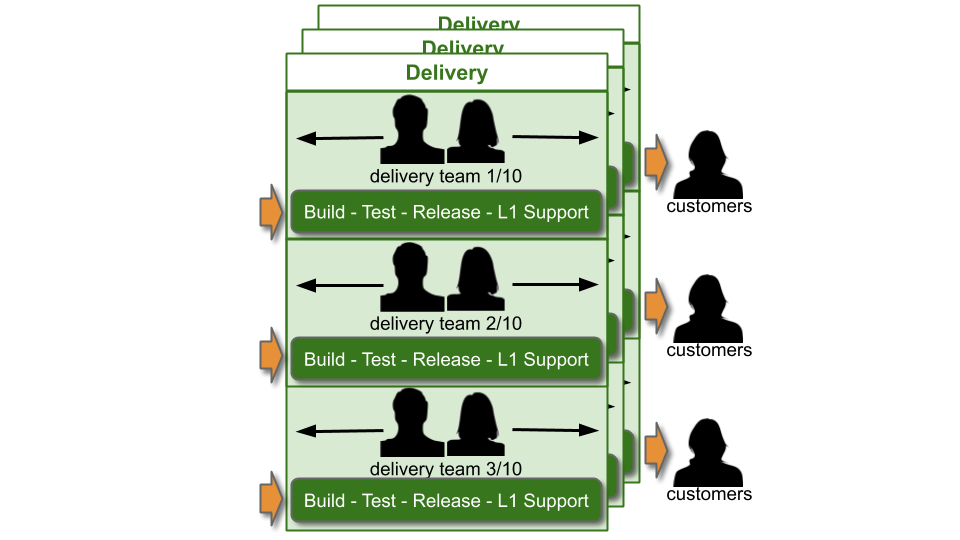
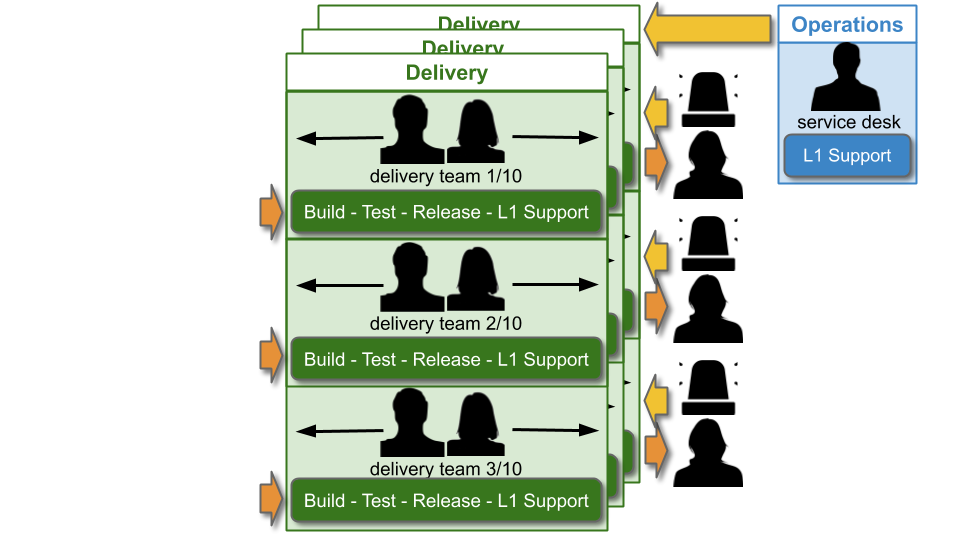
There is an L1 Service Desk team to handle customer requests. Each Delivery team is on L1 support for their applications, and creates their own monitoring dashboard and alerts. There should be a consistent toolchain for anomaly detection and alert notifications for all Delivery teams, that can incorporate those dashboards and alerts.

The Service Desk team will tackle customer complaints and resolve simple technology issues. When an alert fires, a Delivery team will practice Stop The Line by halting feature development, and swarming on the problem within the team. That cross-functional collaboration means a problem can be quickly isolated and diagnosed, and the whole team creates new knowledge they can incorporate into future work. If the Service Desk cannot resolve an issue, they should be able to route it to the appropriate Delivery team via an application mapping in the incident management system.
In On-Call At Any Size, Susan Fowler et al warn “multiple rotations is a key scaling challenge, requiring active attention to ensure practices remain healthy and consistent”. Funding is the first You Build It You Run It practice that needs attention at scale. On-call support for each Delivery team should be charged to the CapEx budget for that team. This will encourage each product manager to regularly work on the delicate trade-off between protecting their desired availability target out of hours and on-call costs. Central OpEx funding must be avoided, as it eliminates the need for product managers to consider on-call costs at all.
Continuous Delivery and Operability at scale
You Build It You Run It has the following advantages at scale:
- Fast incident resolution – an alert will be immediately assigned to the team that owns the application, and can rapidly swarm to recover from failure and minimise TTR
- Short deployment lead times – deployments can be performed on demand by a Delivery team, with no handoffs involved
- Minimal knowledge synchronisation costs – teams can easily convert new operational information into knowledge
- Focus on outcomes – teams are encouraged to work in smaller batches, towards customer outcomes and product hypotheses
- Adaptive architecture – applications can be designed with failure scenarios in mind, including circuit breakers and feature toggles to reduce failure blast radius
- Product telemetry – application dashboards and alerts can be constantly updated to include the latest product metrics
- Situational awareness – teams will have a prior understanding of normal versus abnormal live traffic conditions that can be relied on during incident response
- Fair on-call compensation – team members will be remunerated for the disruption to their lives incurred by supporting applications
In Accelerate, Dr Nicole Forsgren et al found “high performance is possible with all kinds of systems, provided that systems – and the teams that build and maintain them – are loosely coupled”. Accelerate research showed the key to high performance is for a team to be able to independently test and deploy its applications, with negligible coordination with other teams. You Build It You Run It enables a team to increase its throughput and achieve Continuous Delivery, by removing rework and queue times associated with deployments and production support. At scale, You Build It You Run It enables an organisation to increase overall throughput while simultaneously increasing the number of teams. This allows an organisation to move faster as it adds more people, which is a true competitive advantage.
You Build It You Run It creates a healthy engineering culture at scale, in which product development consists of a balance between product ideas and operational features. 10+ Delivery teams with on-call responsibilities will be incentivised to care about operability and consistently meeting availability targets, while increasing delivery throughput to meet product demand. Delivery teams doing 24×7 on-call at scale will be encouraged to build operability into all their applications, from inception to retirement.
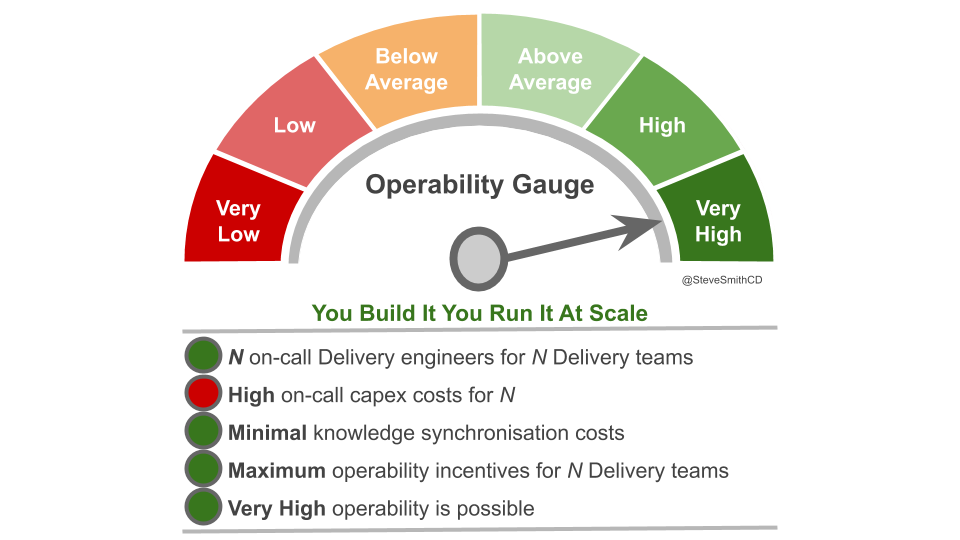
You Build It You Run It can incur high support costs at scale. It can be cost effective if a compromise is struck between deployment targets, operability incentives, and on-call costs that does not weaken operability incentives for Delivery teams.
Production support as revenue insurance
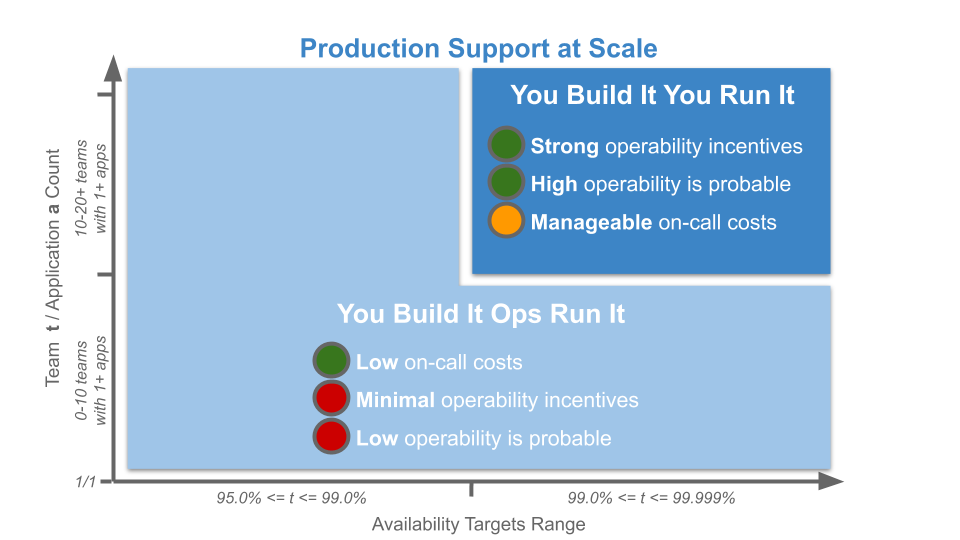
Production support should be thought of as a revenue insurance policy. As insurance policies, You Build It Ops Run It and You Build It You Run It are opposites at scale in terms of risk coverage and costs.
You Build It Ops Run It offers a low degree of risk coverage, limits deployment throughput, and has a potential for revenue loss on unavailability that should not be underestimated. You Build It You Run It has a higher degree of risk coverage, with no limits on deployment throughput and a short TTR to minimise revenue losses on failure.
You Build It You Run It becomes more cost effective as product demand and reliability needs increase, as deployment targets and availability targets are ratcheted up, and the need for Continuous Delivery and operability becomes ever more apparent. The right revenue insurance policy should be chosen based on the number of teams and applications, and the range of availability targets. The fuzzy model below can be used to distinguish when You Build It You Run It is appropriate – when availability targets are demanding and the number of teams and applications is 10+.
The Who Runs It series
- You Build It Ops Run It
- You Build It You Run It
- You Build It Ops Run It at scale
- You Build It You Run It at scale
- You Build It Ops Sometimes Run It
- Implementing You Build It You Run It at scale
- You Build It SRE Run It
Acknowledgements
Thanks to Thierry de Pauw.