I’ve co-authored with Louise Elliott a very polite critique of the Scaled Agile Framework (SAFe), on the Equal Experts website
Author: Steve Smith (Page 2 of 11)
I’ve published a new article on the Equal Experts website, describing why you need alignment with autonomy at scale…
I’ve published a new article on the Equal Experts website, describing 4 ways to successfully scale agile delivery…
I’ve published a new article on the Equal Experts website, describing why product teams still need major incident management…
I’ve published a new article on the Equal Experts website, describing 4 ways to remove the treacle in change management…
“Over the years, I’ve worked with many organisations who transition live software services into an operations team for maintenance mode. There’s usually talk of being feature complete, of costs needing to come under control, and the operations team being the right people for BAU work.
It’s all a myth. You’re never feature complete, you’re not measuring the cost of delay, and you’re expecting your operations team to preserve throughput, reliability, and quality on a shoestring budget.
You can ignore opportunity costs, but opportunity costs won’t ignore you.”
Steve Smith
Introduction
Maintenance mode is when a digital service is deemed to be feature complete, and transitioned into BAU maintenance work. Feature development is stopped, and only fixes and security patches are implemented. This usually involves a delivery team handing over their digital service to an operations team, and then the delivery team is disbanded.
Maintenance mode is everywhere that IT as a Cost Centre can be found. It is usually implemented by teams handing over their digital services to the operations team upon feature completion, and then the teams are disbanded. This happens with the Ops Run It operating model, and with You Build It You Run It as well. Its ubiquity can be traced to a myth:
Maintenance mode by an operations team preserves the same protection for the same financial exposure
This is folklore. Maintenance mode by your operations team might produce lower run costs, but it increases the risk of revenue losses from stagnant features, operational costs from availability issues, and reputational damage from security incidents.
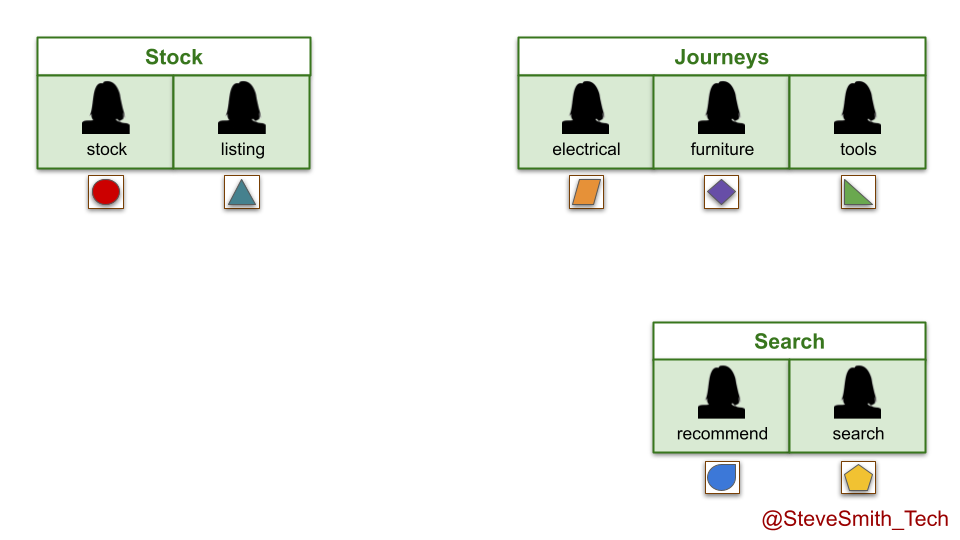
Imagine a retailer DIYers.com, with multiple digital services in multiple product domains. The product teams use You Build It You Run It, and have achieved their Continuous Delivery target measure of daily deployments. There is a high standard of quality and reliability, with incidents rapidly resolved by on-call product team engineers.
DIYers.com digital services are put into maintenance mode with the operations team after three months of live traffic. Product teams are disbanded, and engineers move into newer teams. There is an expected decrease in throughput, from daily to monthly deployments. However, there is also an unexpected decrease in quality and reliability. The operations team handles a higher number of incidents, and takes longer to resolve them than the product teams.
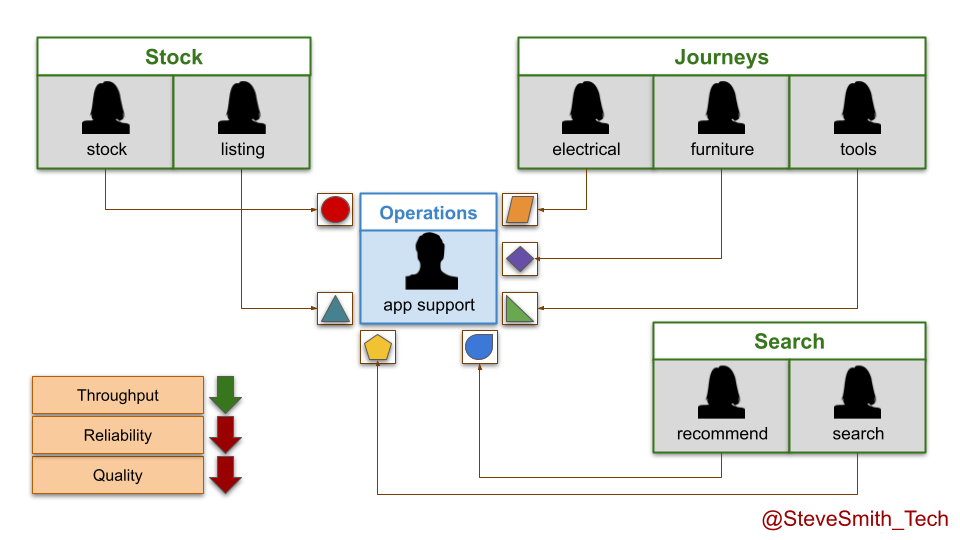
This produces some negative outcomes:
- Higher operational costs. The reduced run costs from fewer product teams are overshadowed by the financial losses incurred during more frequent and longer periods of DIYers.com website unavailability.
- Lower customer revenues. DIYers.com customers are making fewer website orders than before, spending less on merchandise per order, and complaining more about stale website features.
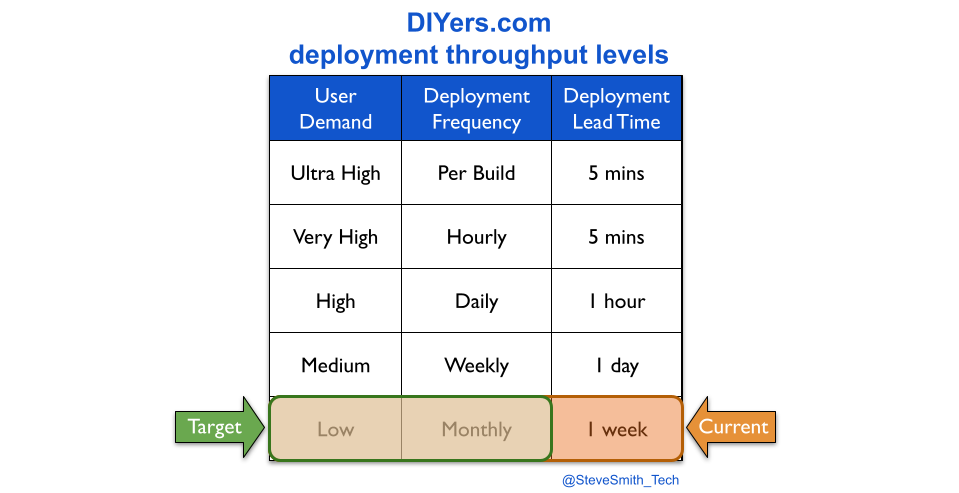
DIYers.com learned the hard way that maintenance mode by an operations team reduces protection, and increases financial exposure.
Maintenance mode reduces protection
Maintenance mode by an operations team reduces protection, because it increases deployment lead times.
Transitioning a digital service into an operations team means fewer deployments. This can be visualised with deployment throughput levels. A You Build It You Run It transition reduces weekly deployments or more to a likely target measure of monthly deployments.
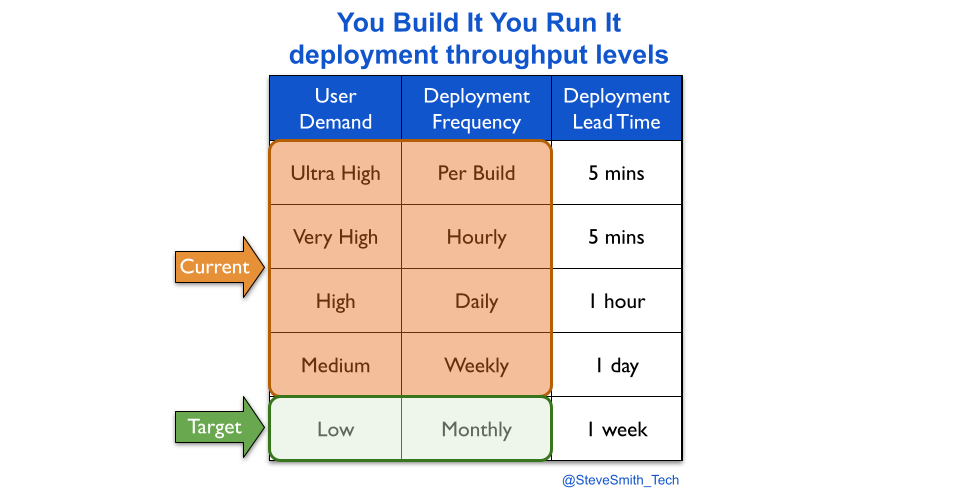
An Ops Run It transition probably reduces monthly deployments to a target measure of quarterly deployments.
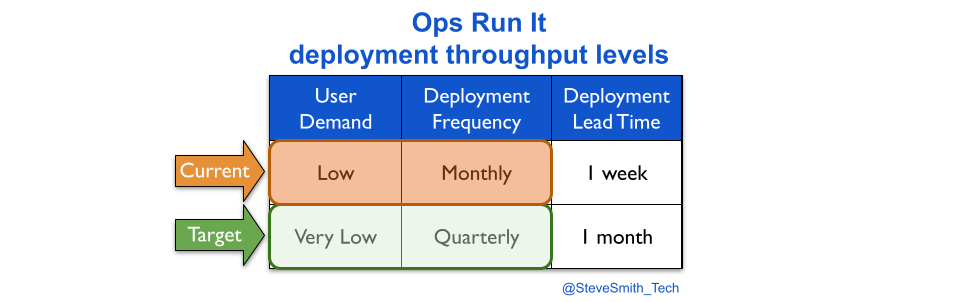
Maintenance mode also results in slower deployments. This happens silently, unless deployment lead time is measured. Reducing deployment frequency creates plenty of slack, and that additional time is consumed by the operations team building, testing, and deploying a digital service from a myriad of codebases, scripts, config files, deployment pipelines, functional tests, etc.
Longer deployment lead times result in:
- Lower quality. Less rigour is applied to technical checks, due to the slack available. Feedback loops become enlarged and polluted, as test suites become slower and non-determinism creeps in. Defects and config workarounds are commonplace.
- Lower reliability. Less time is available for proactive availability management, due to the BAU maintenance workload. More time is needed to identify and resolve incidents. Faulty alerts, inadequate infrastructure, and major financial losses upon failure become the norm.
This situation worsens at scale. Each digital service inflicted on an operations team adds to their BAU maintenance workload. There is a huge risk of burnout amongst operations analysts, and deployment lead times subsequently rising until monthly deployments become unachievable.
At DIYers.com, the higher operational costs were caused by a loss of protection. The drop from daily to monthly deployments was accompanied by a silent drop in deployment lead time from 1 hour to 1 week. This created opportunities for quality and reliability problems to emerge, and operational costs to increase.
Maintenance mode increases financial exposure
Maintenance mode by an operations team increases financial exposure, because opportunity costs are constant, and unmanageable with long deployment lead times.
Opportunity costs are constant because user needs are unbounded. It is absurd to declare a digital service to be feature complete, because user demand does not magically stop when feature development is stopped. Opportunities to profit from satisfying user needs always exist in a market.
Maintenance mode is wholly ignorant of opportunity costs. It is an artificial construct, driven by fixed capex budgets. It is true that developing a digital service indefinitely leads to diminishing returns, and expected return on investment could be higher elsewhere. However, a binary decision to end all investment in a digital service squanders any future opportunities to proactively increase revenues.
Opportunity costs are unmanageable with long deployment times, because a market can move faster than an overworked operations team. The cost of delay can be enormous if days or weeks of effort are needed to build, test, and deploy. Critical opportunities can be missed, such as:
- Increasing revenues by building a few new features to satisfy a sudden, unforeseeable surge in user demand.
- Protecting revenues when a live defect is found, particularly in a key trading period like Black Friday.
- Protecting revenues, costs, and brand reputation when a zero day security vulnerability is discovered.
The log4shell security flaw left hundreds of millions of devices vulnerable to arbitrary code execution. It is easy to imagine operations teams worldwide, frantically trying to patch tens of different digital services they did not build themselves, in the face of long deployment lead times and the threat of serious reputational damage.
At DIYers.com, the lower customer revenues were caused by feature stagnation. The lack of funding for digital services meant customers became dissatisfied with the DIYers.com website, and many of them shopped on competitor websites instead.
Maintenance mode is best performed by product teams
Maintenance mode is best performed by product teams, because they are able to protect the financial exposure of digital services with minimal investment.
Maintenance mode makes sense, in the abstract. IT as a Cost Centre dictates there are only so many fixed capex budgets per year. In addition, sometimes a digital service lacks the user demand to justify continuing with a dedicated product team. Problems with maintenance mode stem from implementation, not the idea. It can be successful with the following conditions:
- Be transparent. Communicate maintenance mode is a consequence of fixed capex budgets, and digital services do not have long-term funding without demonstrating product/market fit e.g. with Net Promoter Score.
- Transition from Ops Run It to You Build It You Run It. Identify any digital services owned by an operations team, and transition them to product teams for all build and run activities.
- Target the prior deployment lead time. Ensure maintenance mode has a target measure of less frequent deployments and the pre-transition deployment lead time.
- Make product managers accountable. Empower budget holders for product teams to transition digital services in and out of maintenance mode, based on business metrics and funding scenarios.
- Block transition routes to operations teams. Update service management policies to state only self-hosted COTS and back office foundational systems can be run by an operations team.
- Track financial exposure. Retain a sliver of funding for user research into fast moving opportunities, and monitor financial flows in a digital service during normal and abnormal operations.
- Run maintenance mode as background tasks. Empower product teams to retain their live digital services, then transfer those services into sibling teams when funding dries up.
Maintenance mode works best when product teams run their own digital services. If a team has a live digital service #1 and new funding to develop digital service #2 in the same product domain, they monitor digital service #1 on a daily basis and deploy fixes and patches as necessary. This gives product teams a clear understanding of the pitfalls and responsibilities of running a digital service, and how to do better in the future.
If funding dictates a product team is disbanded or moved into a different product domain, any digital services owned by that team need to be transferred to a sibling team in the current product domain. This minimises the knowledge sharing burden and BAU maintenance workload for the new product team. It also protects deployment lead times for the existing digital services, and consequently their reliability and quality standards.
Maintenance mode by product teams requires funding for one permanent product team in each product domain. This drives some positive behaviours in organisational design. It encourages teams working in the same product domain to be sited in the same geographic region, which encourages a stronger culture based on a shared sense of identity. It also makes it easier to reawaken a digital service, as the learning curve is much smaller when sufficient user demand is found to justify further development.
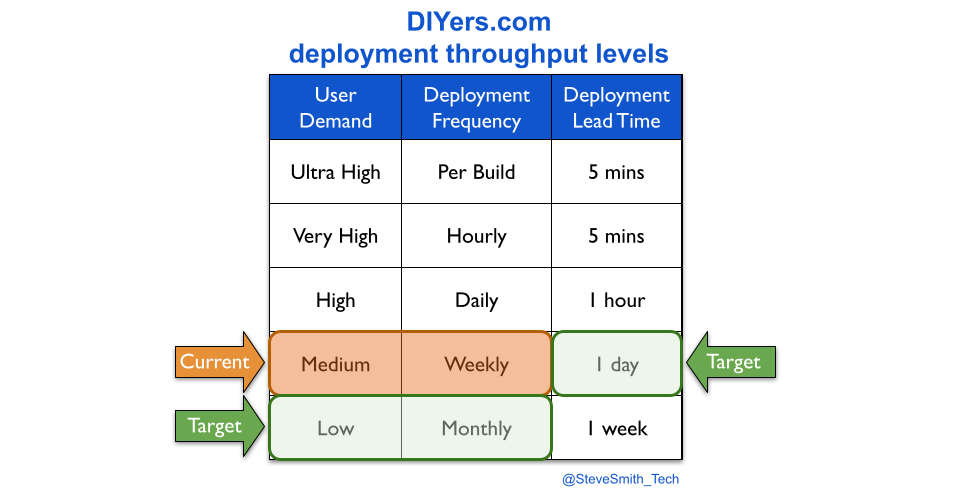
Consider DIYers.com, if maintenance mode was by owned product teams. The organisation-wide target measures for maintenance mode would be expanded, from monthly deployments to monthly deployments performed in under a day.
In the stock domain, the listings team is disbanded when funding ends. Its live service is moved into the stock team, and runs in the background indefinitely while development efforts continue on the stock service. The same happens in the search domain, with the recommend service moving into the search team.
In the journeys domain, the electricals and tools teams both run out of funding. Their live digital services are transferred into the furniture team, which is renamed the journeys team and made accountable for all live digital services there.
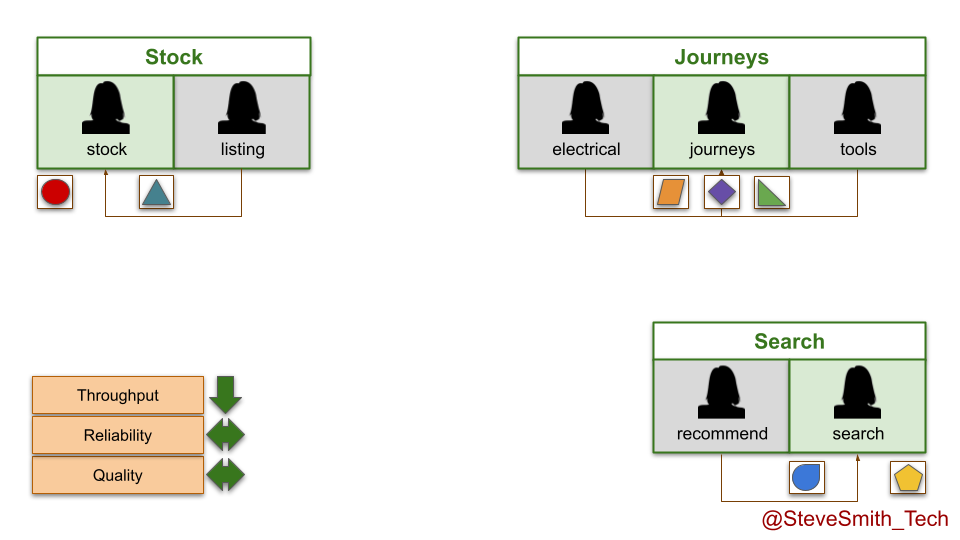
Of course, there is another option for maintenance mode by product teams. If a live digital service is no longer competitive in the marketplace and funding has expired, it can be deleted. That is the true definition of done.
I’ve published a new article on the Equal Experts website, describing 5 ways to minimise your run costs with You Build It You Run It…
I’ve published a new article on the Equal Experts website, describing how to decide when to use You Build It You Run It (and when not to use it)…
“In 2017, I dismissed GitOps as a terrible portmanteau for Kubernetes Infrastructure as Code. Since then, Weaveworks has dialled up the hype, and GitOps is now promoted as a developer experience as well as a Kubernetes operating model.
I dislike GitOps because it’s a sugar pill, and it’s marketed as more than a sugar pill. It’s just another startup sharing what’s worked for them. It’s one way of implementing Continuous Delivery with Kubernetes. Its ‘best practices’ aren’t best for everyone, and can cause problems.
The benefits of GitOps are purely transitive, from the Continuous Delivery principles and Infrastructure as Code practices implemented. It’s misleading to suggest GitOps has a new idea of substance. It doesn’t.
Steve Smith
TL;DR:
GitOps is defined by Weaveworks as ‘a way to do Kubernetes cluster management and application delivery’.
A placebo is defined by Merriam Webster as ‘a usually pharmacologically inert preparation, prescribed more for the mental relief of the patient than for its actual effect on a disorder’.
GitOps is a placebo. Its usage may make people happy, but it offers nothing that cannot be achieved with Continuous Delivery principles and Infrastructure as Code practices as is.
An unnecessary rebadging
In 2017, Alexis Richardson of Weaveworks coined the term GitOps in Operations by Pull Request. He defined GitOps as:
- AWS resources and Kubernetes infrastructure are declarative.
- The entire system state is version controlled in a single Git repository.
- Operational changes are made by GitHub pull request into a deployment pipeline.
- Configuration drift detection and correction happen via kubediff and Weave Flux.
The Weaveworks deployment and operational capabilities for their Weave Cloud product are outlined, including declarative Kubernetes configuration in Git and a cloud native stack in AWS. There is an admirable caveat of ‘this is what works for us, and you may disagree’, which is unfortunately absent in later GitOps marketing.
As a name, GitOps is an awful portmanteau, ripe for confusion and misinterpretation. Automated Kubernetes provisioning does not require ‘Git’, nor does it encompass all the ‘Ops’ activities required for live user traffic. It is a small leap to imagine organisations selling GitOps implementations that Weaveworks do not recognise as GitOps.
As an application delivery method, GitOps offers nothing new. Version controlling declarative infrastructure definitions, correcting configuration drift, and monitoring infrastructure did not originate from GitOps. In their 2010 book Continuous Delivery, Dave Farley and Jez Humble outlined infrastructure management principles:
- Declarative. The desired state of your infrastructure should be specified through version controlled configuration.
- Autonomic. Infrastructure should correct itself to the desired state automatically.
- Monitorable. You should always know the actual state of your infrastructure through instrumentation and monitoring.
The DevOps Handbook by Gene Kim et al in 2016 included the 2014 State Of DevOps Report comment that ‘the use of version control by Ops was the highest predictor of both IT and organisational performance’, and it recommended a single source of truth for the entire system. In the same year, Kief Morris established infrastructure definition practices in Infrastructure as Code 1st Edition, and reaffirmed them in 2021 in Infrastructure as Code 2nd Edition.
GitOps is simply a rebadging of Continuous Delivery principles and Infrastructure as Code practices, with a hashtag for a name and contemporary tools. Those principles and practices predate GitOps by some years.
No new ideas of substance
In 2018, Weaveworks published their Guide to GitOps, to explain how GitOps differs from Continuous Delivery and Infrastructure as Code. GitOps is redefined as ‘an operating model for Kubernetes’ and ‘a path towards a developer experience for managing applications’. Its principles are introduced as:
- The entire system described declaratively.
- The canonical desired system state versioned in Git.
- Approved changes that can be automatically applied to the system.
- Software agents to ensure correctness and alert on divergence.
These are similar to the infrastructure management principles in Continuous Delivery.
GitOps best practices are mentioned, and expanded by Alexis Richardson in What is GitOps. They include declaring per-environment target states in a single Git repository, monitoring Kubernetes clusters for state divergence, and continuously converging state between Git and Kubernetes via Weave Cloud. These are all sound Infrastructure as Code practices for Kubernetes. However, positioning them as best practices for continuous deployment is wrong.
What works for Weaveworks will not necessarily work in other organisations, because each organisation is a complex, adaptive system with its own unique context. Continuous Delivery needs context-rich, emergent practices, borne out of heuristics and experimentation. Context-free, prescriptive best practices are unlikely to succeed. Examples include:
- Continuous deployment. Multiple deployments per day can be an overinvestment. If customer demand is satisfied by fortnightly deployments or less, separate developer and operations teams might be viable. In that scenario, Kubernetes is a poor choice, as both teams would need to understand it well for their shared deployment process.
- Declarative configuration. There is no absolute right or wrong in declarative versus imperative configuration. Declarative infrastructure definitions can become thousands of lines of YAML, full of unintentional complexity. It is unwise to mandate either paradigm for an entire toolchain.
- Feature branching. Branching in an infrastructure repository can encourage large merges to main, and/or long-lived per-environment branches. Both are major impediments to Continuous Delivery. The DevOps Handbook notes the 2015 State Of DevOps Report showed ‘trunk-based development predicts higher throughput and better stability, and even higher job satisfaction and lower rates of burnout’.
- Source code deployments. Synchronising source code directly with Kubernetes clusters violates core deployment pipeline practices. Omitting versioned build packages makes it easier for infrastructure changes to reach environments out of order, and harder for errors to be diagnosed when they occur.
- Kubernetes infatuation. Kubernetes can easily become an operational burden, due to its substantial onboarding costs, steep learning curve, and extreme configurability. It can be hard to justify investing in Kubernetes, due to the total cost of ownership. Lightweight alternatives exist, such as AWS Fargate and GCP Cloud Run.
The article has no compelling reason why GitOps differs from Continuous Delivery or Infrastructure as Code. It claims GitOps creates a freedom to choose the tools that are needed, faster deployments and rollbacks, and auditable functions. Those capabilities were available prior to GitOps. GitOps has no new ideas of substance.
Transitive and disputable benefits
In 2021, Weaveworks published How GitOps Boosts Business Performance: The Facts. GitOps is redefined as ‘best practices and an operational model that reduces the complexity of Kubernetes and makes it easier to deliver on the promise of DevOps’. The Weave Kubernetes Platform product is marketed as the easiest way to implement GitOps.
The white paper lists the benefits of GitOps:
- Increased productivity – ‘mean time to deployment is reduced significantly… teams can ship 30-100 times more changes per day’
- Familiar developer experience – ‘they can manage updates and introduce new features more rapidly without expert knowledge of how Kubernetes works’
- Audit trails for compliance – ‘By using Git workflows to manage all deployments… you automatically generate a full audit log’
- Greater reliability – ‘GitOps gives you stable and reproducible rollbacks, reducing mean time to recovery from hours to minutes’
- Consistent workflows – ‘GitOps has the potential to provide a single, standardised model for amending your infrastructure’
- Stronger security guarantees – ‘Git already offers powerful security guarantees… you can secure the whole development pipeline’
The white paper also explains the State of DevOps Report 2019 by Dr. Nicole Forsgren et al, which categorises organisations by their Software Delivery and Operational (SDO) metrics. There is a description of how GitOps results in a higher deployment frequency, reduced lead times, a lower change failure rate, reduced time to restore service, and higher availability. There is a single Weaveworks case study cited, which contains limited data.
These benefits are not unique to GitOps. They are transitive. They are sourced from implementing Continuous Delivery principles and Infrastructure as Code practices upstream of GitOps. Some benefits are also disputable. For example, Weaveworks do not cite any data for their increased productivity claim of ‘30-100 times more changes per day’, and for many organisations operational workloads will not be the biggest source of waste. In addition, developers will need some working knowledge of Kubernetes for incident response at least, and it is an arduous learning curve.
Summary
GitOps started out in 2017 as Weaveworks publicly sharing their own experiences in implementing Infrastructure as Code for Kubernetes, which is to be welcomed. Since 2018, GitOps has morphed into Weaveworks marketing a new application delivery method that offers nothing new.
GitOps is simply a rebadging of 2010 Continuous Delivery principles and 2016 Infrastructure as Code practices, applied to Kubernetes. Its benefits are transitive, sourced from implementing those principles and practices that came years before GitOps. Some of those benefits can also be disputed.
GitOps is well on its way to becoming the latest cargo cult, as exemplified by Weaveworks announcing a GitOps certification scheme. It is easy to predict the inclusion of a GitOps retcon that downplays Kubernetes, so that Weaveworks can future proof their sugar pill from the inevitable decline in Kubernetes demand.
References
- Continuous Delivery [2010] by Dave Farley and Jez Humble
- The DevOps Handbook [2016] by Gene Kim et al
- Infrastructure as Code: Managing Servers in the Cloud [2016] by Kief Morris
- Operations by Pull Request [2017] by Alexis Richardson
- Guide to GitOps [2018] by Weaveworks
- What is GitOps Really [2018] by Alexis Richardson
- How GitOps boosts business performance – the facts [2021] by Weaveworks
- Infrastructure as Code: Dynamic Systems for the Cloud Age [2021] by Kief Morris
Acknowledgements
Thanks to Dave Farley, Kris Buytaert, and Thierry de Pauw for their feedback.
“Is it possible to overinvest in Continuous Delivery?
The benefits of Continuous Delivery are astonishing, so it’s tempting to say no. Keep on increasing throughput indefinitely, and enjoy the efficiency gains! But that costs time and money, and if you’re already satisfying customer demand… should you keep pushing so hard?
If you’ve already achieved Continuous Delivery, sometimes your organisation should invest its scarce resources elsewhere – for a time. Continuously improve in the fuzzy front end of product development, as well as in technology.”
Steve Smith
TL;DR:
- Deployment throughput levels describe the effort necessary to implement Continuous Delivery in an enterprise organisation.
- Investing in Continuous Delivery means experimenting with technology and organisational changes to find and remove constraints in build, testing, and operational activities.
- When such a constraint does not exist, it is possible to overinvest in Continuous Delivery beyond the required throughput level.
Introduction
Continuous Delivery means increasing deployment throughput until customer demand is satisfied. It involves radical technology and organisational changes. Accelerate by Dr. Nicole Forsgren et al describes the benefits of Continuous Delivery:
- A faster time to market, and increased revenues.
- A substantial improvement in technical quality, and reduced costs.
- An uptick in profitability, market share, and productivity.
- Improved job satisfaction, and less burnout for employees.
If an enterprise organisation has IT as a Cost Centre, funding for Continuous Delivery is usually time-limited and orthogonal to development projects. Discontinuous Delivery and a historic underinvestment in continuous improvement are the starting point.
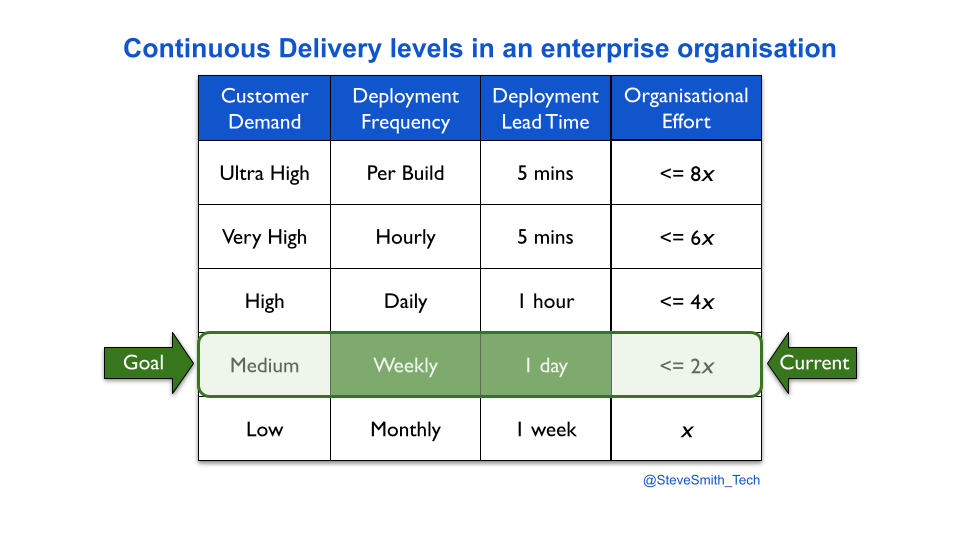
Continuous Delivery levels provide an estimation heuristic for different levels of deployment throughput versus organisational effort. A product manager might hypothesise their product has to move from monthly to weekly deployments, in order to satisfy customer demand. It can be estimated that implementing weekly deployments would take twice as much effort as monthly deployments.

Once the required throughput level is reached, incremental improvement efforts need to be funded and completed as business as usual. This protects ongoing deployment throughput, and the satisfaction of customer demand. The follow-up question is then how much more time and money to spend on deployment throughput. This can be framed as:
Is it possible to overinvest in Continuous Delivery?
To answer this question, a deeper understanding of how Continuous Delivery happens is necessary.
Investing with a deployment constraint
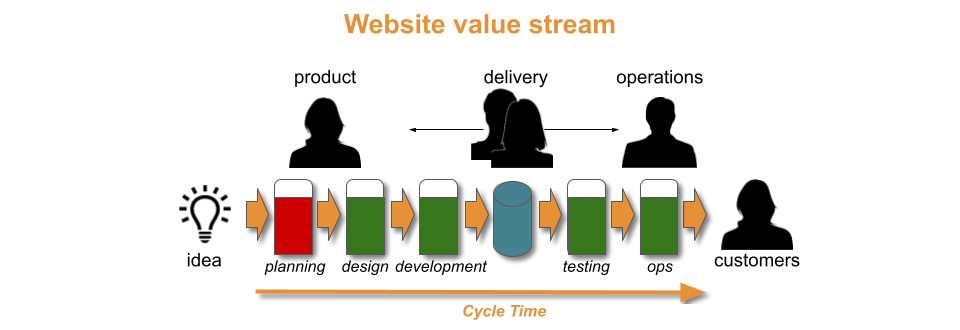
In an organisation, a product traverses a value stream with a fuzzy front end of design and development activities, and a technology value stream of build, testing, and operational activities.
With a Theory Of Constraints lens, Discontinuous Delivery is caused by a constraint within the technology value stream. Time and money must be invested in technology and organisational changes from the Continuous Delivery canon, to find and remove that constraint. An example would be from You Build It Ops Run It, where a central operations team cannot keep up with deployment requests from a development team.
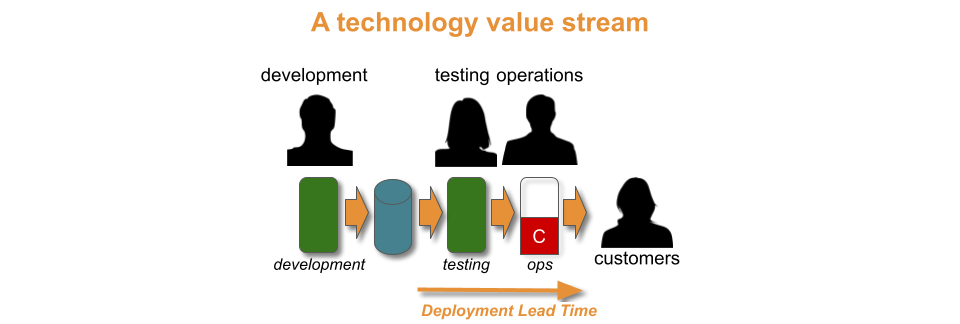
The optimal approach to implementing Continuous Delivery is the Improvement Kata. Improvement cycles are run to experiment with different changes. This continues until all constraints in the technology value stream are removed, and the flow of release candidates matches the required throughput level.
The overinvestment question can now be qualified as:
Is it possible to overinvest in Continuous Delivery, once constraints on deployment throughput are removed and customer demand is satisfied?
The answer depends on the amount of time and money to be invested, and where else that investment could be made in the organisation.
Investing without a deployment constraint
Indefinite investment in Continuous Delivery is possible. The deployment frequency and deployment lead time linked to a throughput level are its floor, not its ceiling. For example, a development team at its required throughput level of weekly deployments could push for a one hour deployment lead time.

Deployment lead time strongly correlates with technical quality. An ever-faster deployment lead time tightens up feedback loops, which means defects are found sooner, rework is reduced, and efficiency gains are accrued. The argument for a one hour deployment lead time is to ensure a developer receives feedback on their code commits within the same day, rather than the next working day with a one day deployment lead time.
Advocating for a one hour deployment lead time that exceeds the required throughput level is wrong, due to:
- Context. A one day deployment lead time might mean eight hours waiting for test feedback from an overnight build, before a 30 minute automated deployment to production. Alternatively, it might mean a 30 minute wait for automated tests to complete, before an eight hour manual deployment. A developer might receive actionable feedback on the same day.
- Cost. Incremental improvements are insufficient for a one hour deployment lead time. Additional funding is inevitably needed, as radical changes in build, testing, and operational activities are involved. In Lean Manufacturing, this is the difference between kaizen and kaikaku. It is the difference between four minutes refactoring a single test in an eight hour test suite, and four weeks parallelising all those tests into a 30 minute execution time.
- Culture. Radical changes necessary for a one hour deployment lead time can encounter strong resistance when customer demand is already satisfied, and there is no unmet business outcome. The lack of business urgency makes it easier for people to refuse changes, such as a change management team declining to switch from a pre-deployment CAB approval to a post-deployment automated audit trail.
- Constraints. A one hour deployment lead time exceeding the required throughput level is outside Discontinuous Delivery. There is no constraint to find and remove in the technology value stream. There is instead an upstream constraint in the fuzzy frontend. Time and money would be better invested in business development or product design, rather than Continuous Delivery. Removing the fuzzy frontend constraint could shorten the cycle time for product ideas, and uncover new revenue streams.
The correlation between deployment lead time and technical quality makes an indefinite investment in Continuous Delivery tempting, but overinvestment is a real possibility. Redirecting continuous improvement efforts at the fuzzy frontend after Continuous Delivery has been achieved is the key to unlocking more customer demand, raising the required throughput level, and creating a whole new justification for funding further Continuous Delivery efforts.
Example – Gardenz
Gardenz is a retailer. It has an ecommerce website that sells garden merchandise. It takes one week to deploy a new website version, and it happens once a month. The product manager estimates weekly deployments of new product features would increase customer sales.
The Gardenz website is in a state of Discontinuous Delivery, as the required throughput level is unmet. The developers previously needed five days to establish monthly deployments, so ten days is estimated for weekly.

The Gardenz constraint is manual regression testing. It causes so much rework between developers and testers that deployment lead time cannot be less than one week.
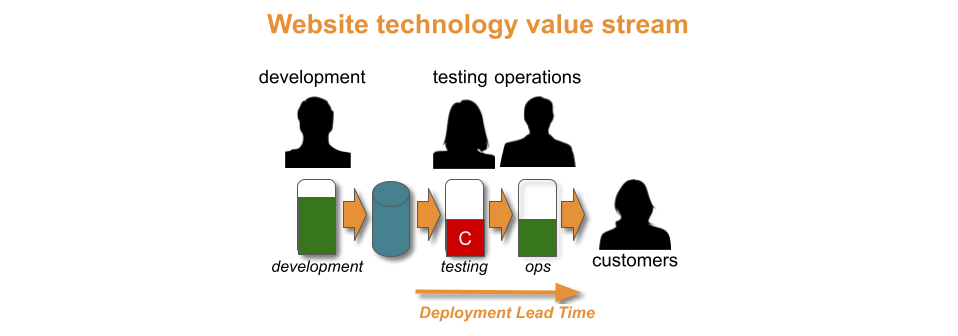
The Gardenz developers and testers run improvement cycles to merge into a single delivery team, and replace their manual regression tests with automated functional tests. After fourteen days of effort, a deployment lead time of one day is possible. This allows the website to be deployed once a week, in under a day.
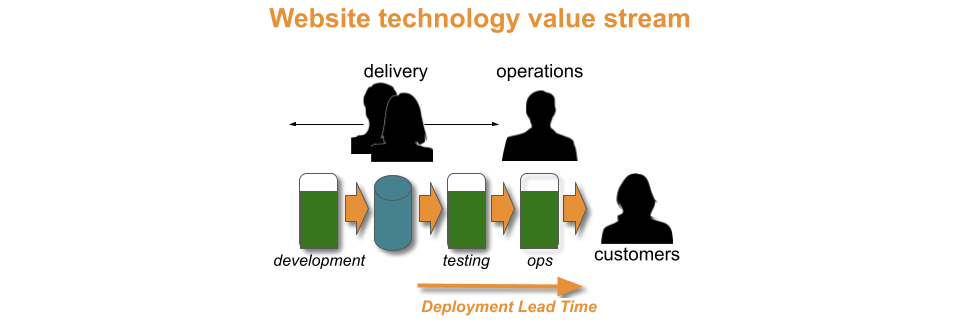
Gardenz has moved up a throughput level to weekly deployments, and the product manager is satisfied. Now they need to decide whether to invest further in daily deployments, beyond customer demand. As weekly deployments took 14 days, 28 days of time and money can be estimated for daily.
The removal of the testing constraint on weekly deployments causes a planning constraint to emerge for daily deployments. New feature ideas cannot move through product planning faster than two days, no matter whether the deployment lead time is one day, one hour, or one minute. The product manager decides to invest the available time and money into removing the planning constraint. Daily deployments are earmarked for future consideration.
Example – Puzzle Planet
Puzzle Planet is a media publisher. Every month, it sells a range of puzzle print magazines to newsagent resellers. Its magazines come from a fully automated content pipeline. It takes one day for a magazine to be automatically created and published to print distributors.
The Puzzle Planet content pipeline is in a state of Continuous Delivery. The required throughput level of monthly magazines is met. It took two developers six months to reach a one week content lead time, and a further nine months to exceed the throughput level with a one day content lead time.

There is no constraint within the content pipeline. The content pipeline also serves a subscription-based Puzzle Planet app for mobile devices, in an attempt to enter the digital puzzle market. Subscribers receive new puzzles each day, and an updated app version every two months. Uptake of the app is limited, and customer demand is unclear.
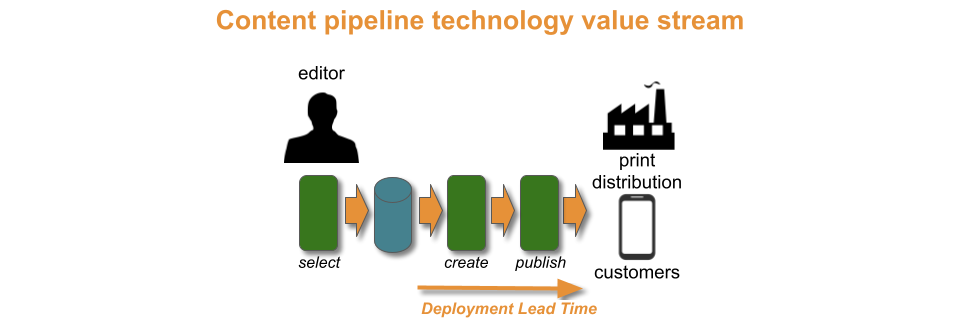
Puzzle Planet has benefitted from exceeding its required throughput level with a one day content lead time. The content pipeline is highly efficient. It produces high quality puzzles with near-zero mistakes, and handles print distributors with no employee costs. It could theoretically scale up to hundreds of magazine titles. However, a one week content lead time would serve similar purposes.
The problem is the lack of customer demand for the Puzzle Planet app. Digital marketing is the constraint for Puzzle Planet, not its content pipeline or print magazines. An app with few customers and bi-monthly features will struggle in the marketplace, regardless of content updates.
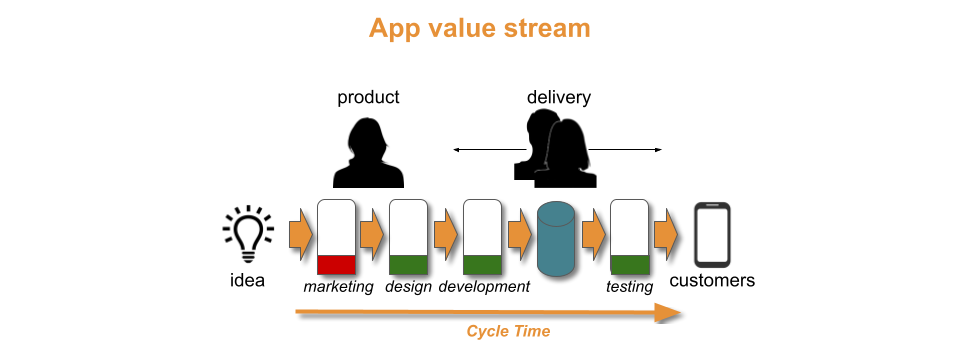
As it stands, the nine months spent on a one day content lead time was an overinvestment in Continuous Delivery. The nine months of funding for the content pipeline could have been invested in digital marketing instead, to better understand customer engagement, retention, and digital revenue opportunities. If more paying customers can be found for the Puzzle Planet app, the one day content lead time could be turned around into a worthy investment.
Acknowledgements
Thanks to Adam Hansrod for his feedback.