The Version Control Strategies series
- Organisation Antipattern – Release Feature Branching
- Organisation Pattern – Trunk Based Development
- Organisation Antipattern – Integration Feature Branching
- Organisation Antipattern – Build Feature Branching
Release Feature Branching dramatically increases development costs and risk
Feature Branching is a version control practice in which developers commit their changes to a branch of a source code repository before merging to trunk at a later date. Popularised in the 1990s and 2000s by centralised Version Control Systems (VCS) such as ClearCase, Feature Branching has evolved over the years and is currently enjoying a resurgence in popularity thanks to Distributed Version Control Systems (DVCS) such as Git.
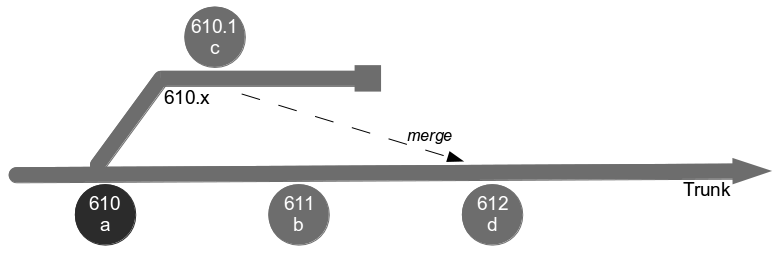
The traditional form of Feature Branching originally promoted by ClearCase et al might be called Release Feature Branching. The central branch known as trunk is considered a flawless representation of all previously released work, and new features for a particular release are developed on a long-lived branch. Developers commit changes to their branch, automated tests are executed, and testers manually verify the new features. Those features are then released into production from the branch, merged into trunk by the developers, and regression tested on trunk by the testers. The branch can then be earmarked for deletion and should only be used for production defect fixes.
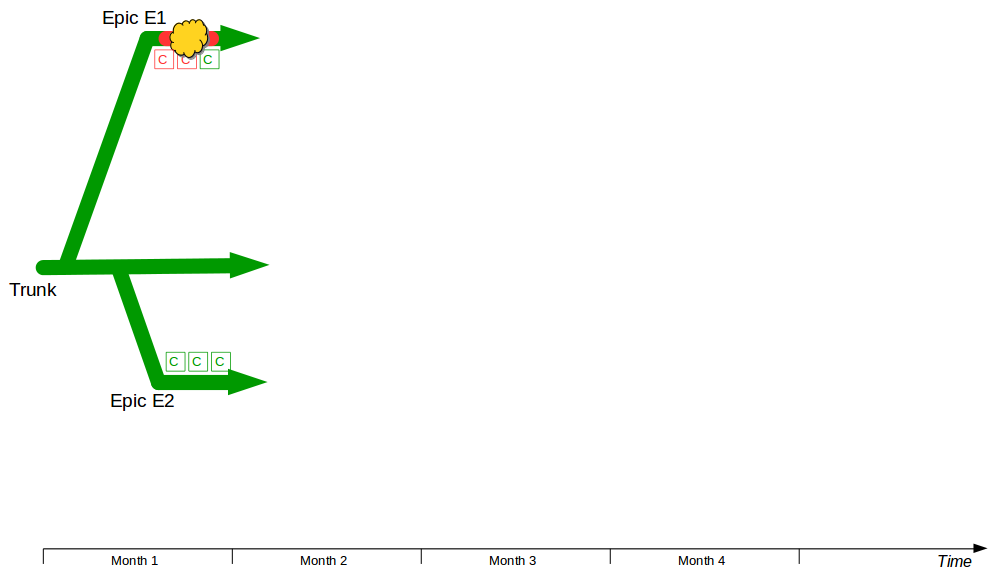
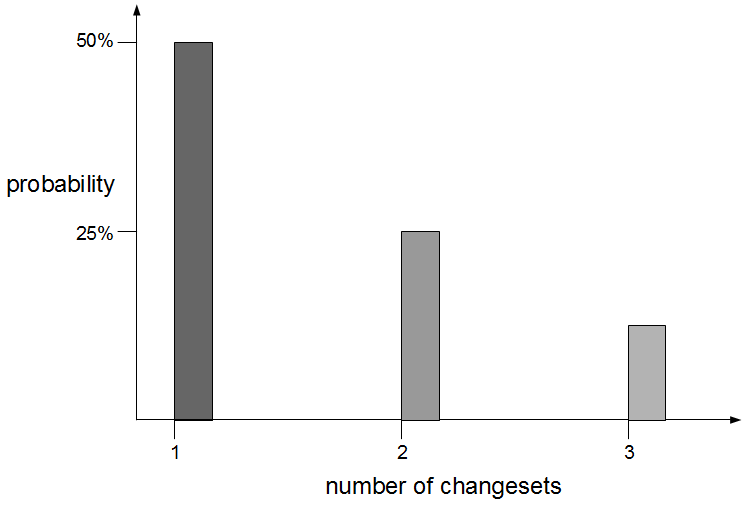
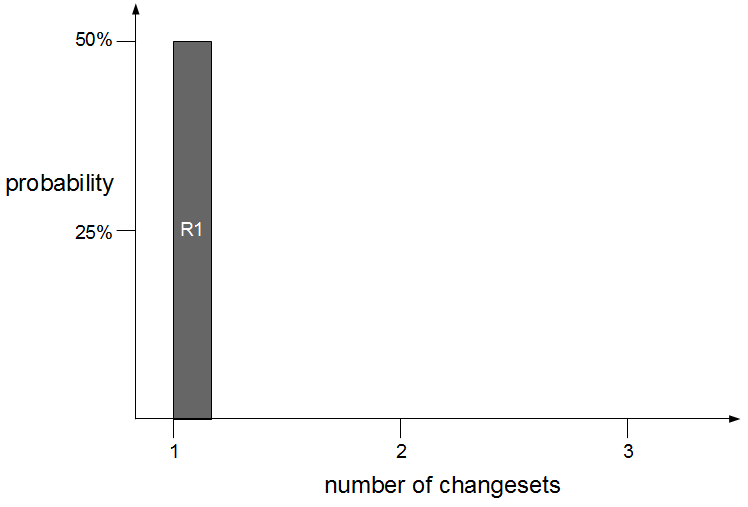
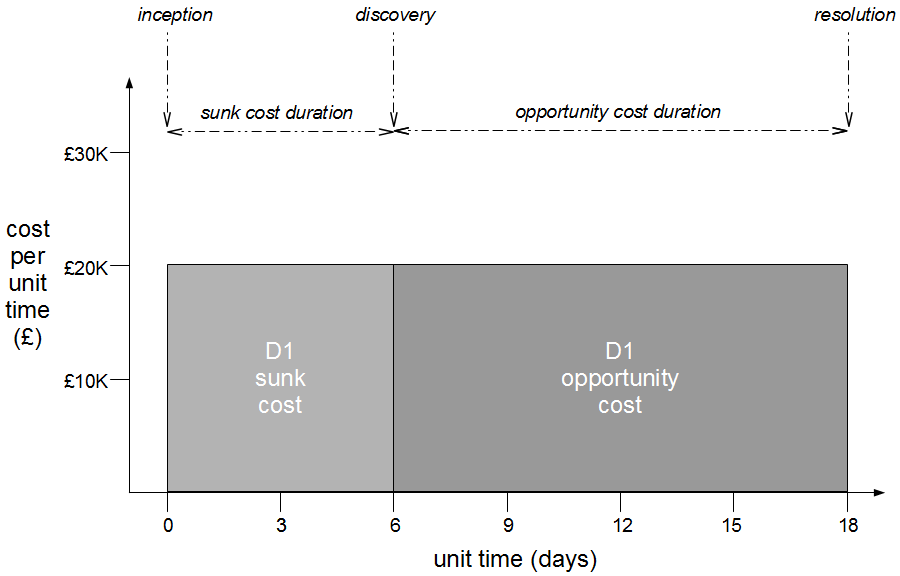
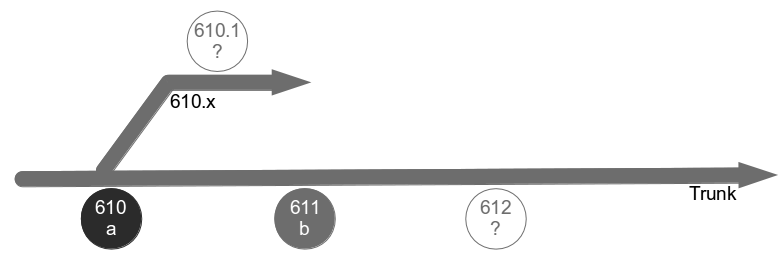
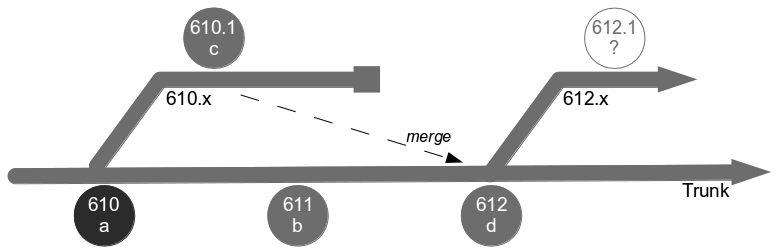
Consider an organisation that provides an online company accounts service, with its codebase maintained by a team practicing Release Feature Branching. Two epics – E1 Corporation Tax and E2 Trading Losses – begin development on concurrent feature branches. The E1 branch is broken early on, but E2 is unaffected and carries on regardless.
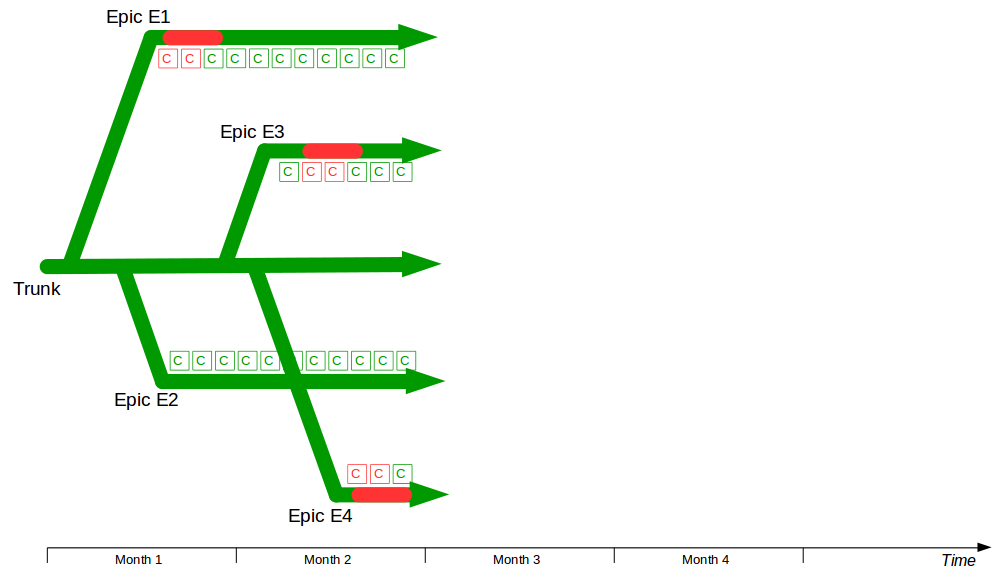
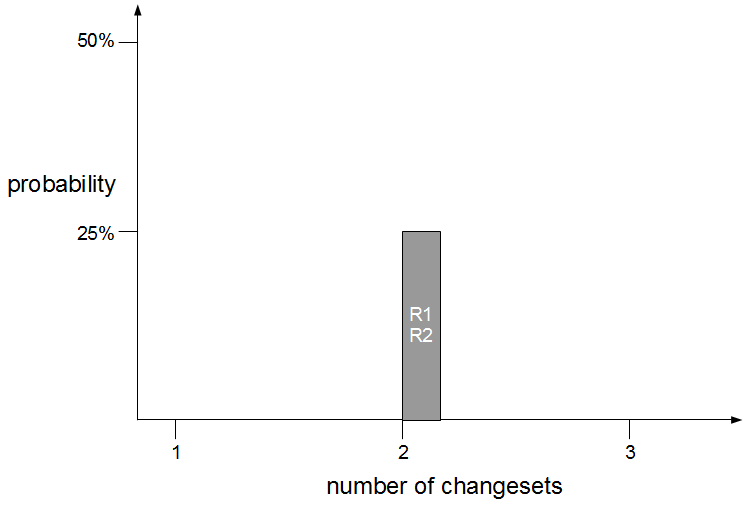
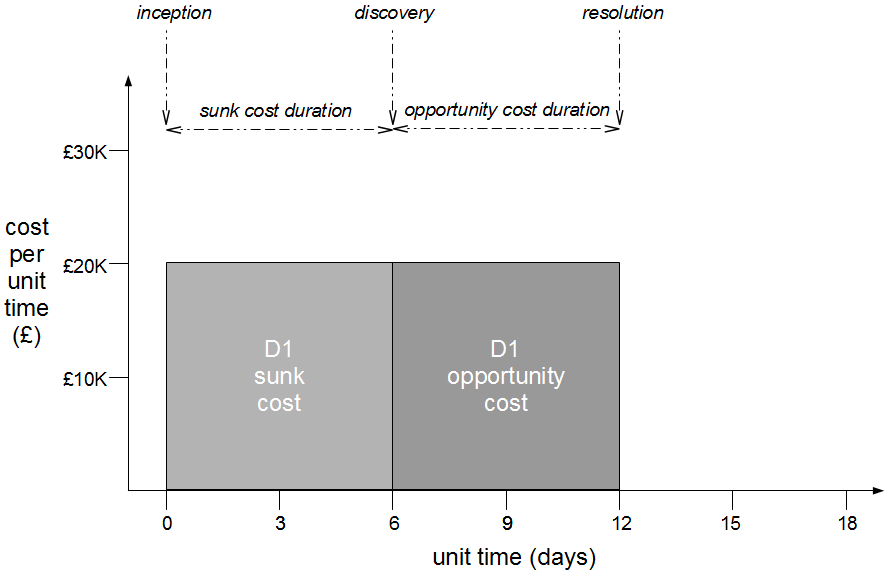
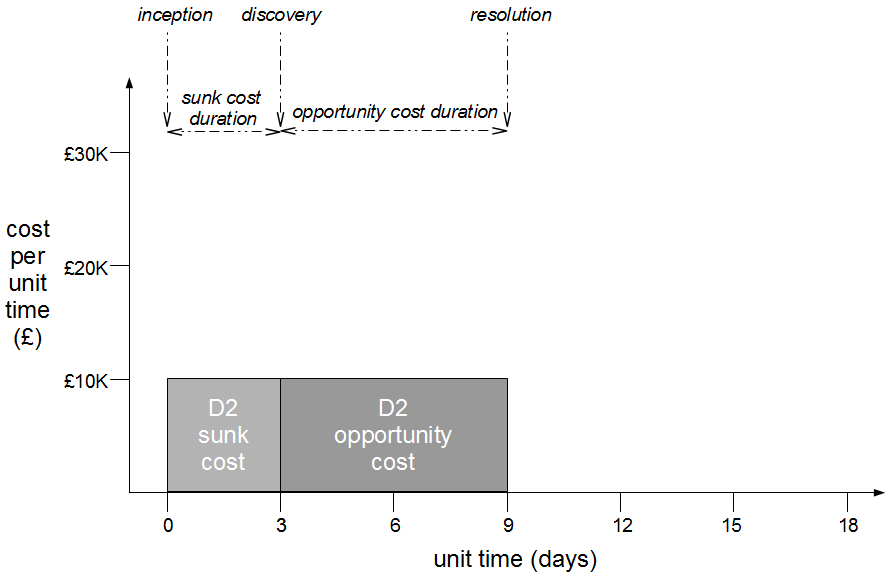
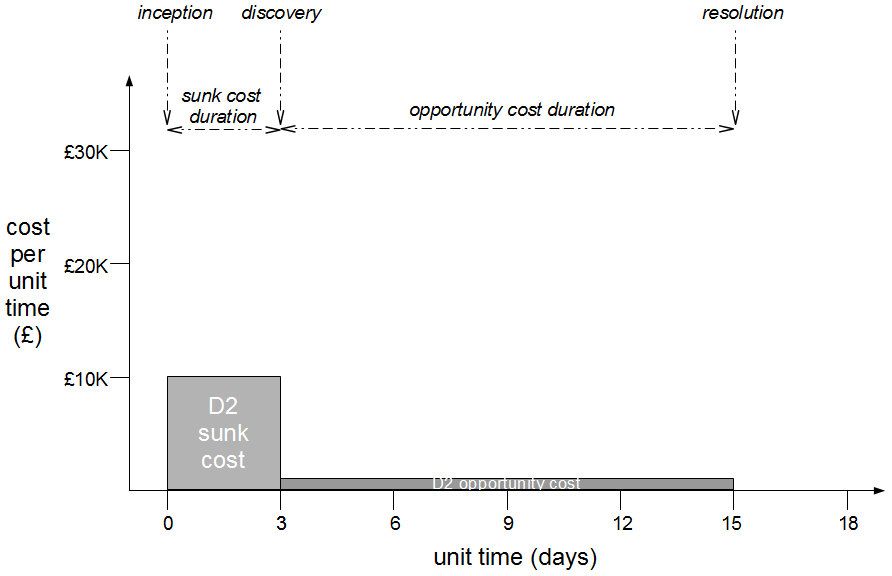
In month 2, two more epics – E3 Statutory Accounts and E4 Participator Loans – begin. E3 is estimated to have a low impact but its branch is broken by a refactoring and work is rushed to meet the E3 deadline. Meanwhile the E4 branch is broken by a required architecture change and gradually stabilised.
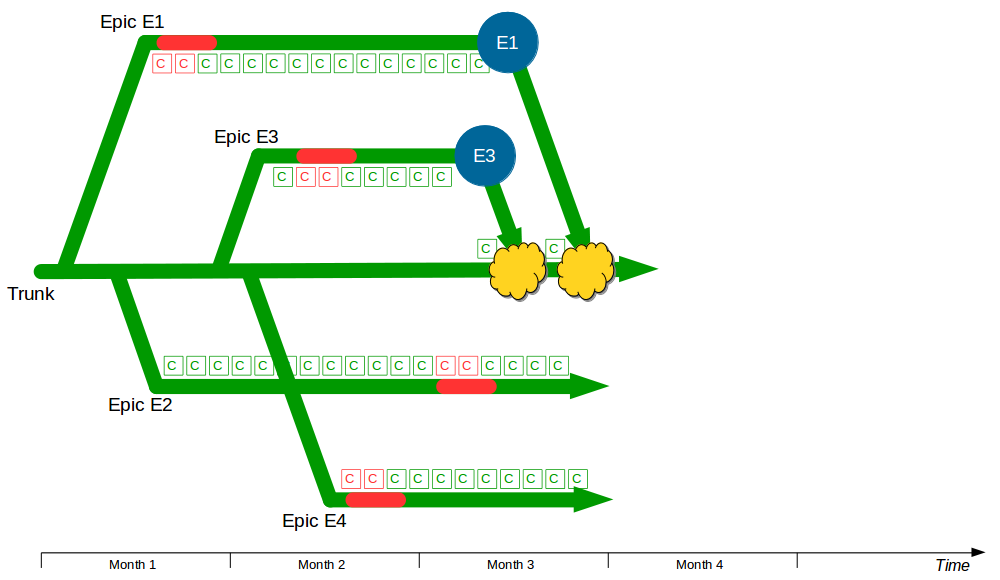
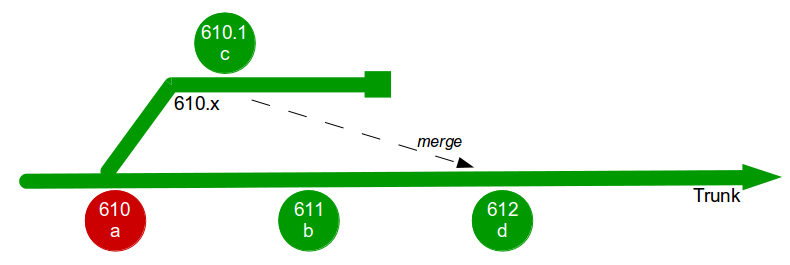
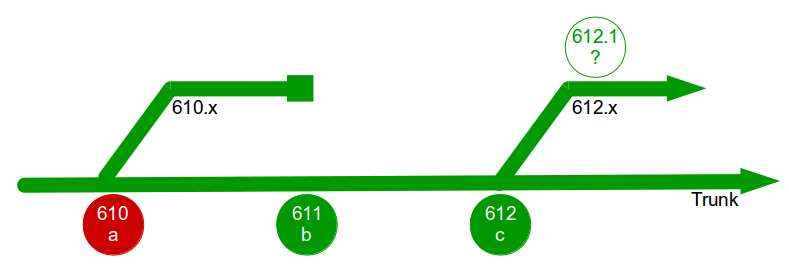
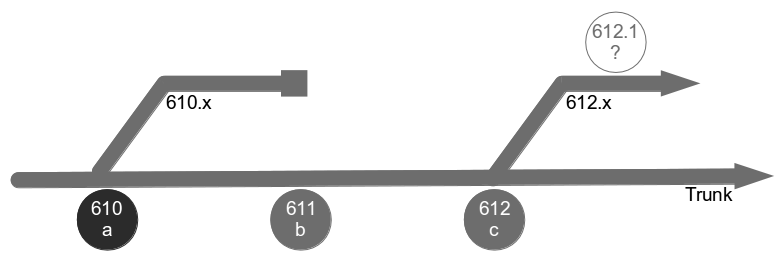
In month 3, E3 is tested and released into production before being merged into trunk and regression tested. The E2 branch becomes broken so progress halts until it is fixed. The E1 branch is tested and released into production before the merge and regression testing of trunk + E3 + E1.
In month 4, E2 is tested and released into production but the subsequent merge and regression testing of trunk + E3 + E1 + E2 unexpectedly fails. While the E2 developers fix trunk E4 is tested and released, and once trunk is fixed the merge and regression testing of trunk + E3 + E1 + E2 + E4 is performed. Soon afterwards a critical defect is found in E4, so a E4.1 fix is also released.
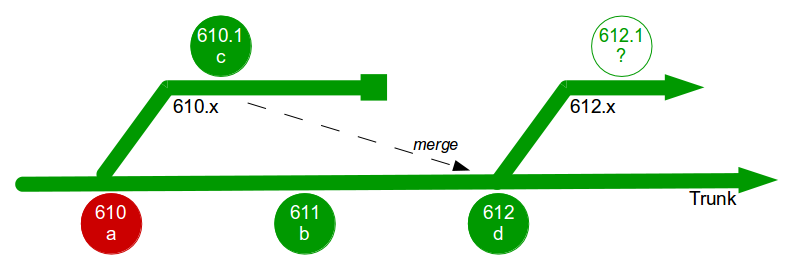
At this point all 4 feature branches could theoretically be deleted, but Corporation Tax changes are requested for E1 on short notice and a trunk release is refused by management due to the perceived risk. The dormant E1 branch is resurrected so E1.1 can be released into production and merged into trunk. While the E1 merge was trunk + E3 the E1.1 merge is trunk + E3 + E2 + E4.1, resulting in a more complex merge and extensive regression testing.
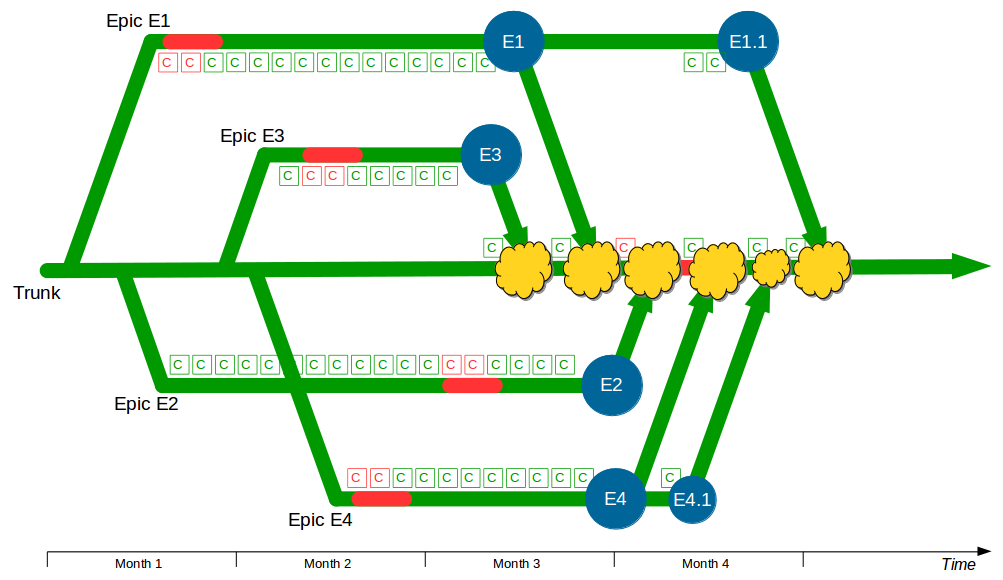
In this example E1, E2, E3, and E4 enjoyed between 1 and 3 months of uninterrupted development, and E4 was even released into production while trunk was broken. However, each period of isolated development created a feedback delay on trunk integration, and this was worsened by the localisation of design activities such as the E3 refactoring and E4 architectural change. This ensured merging and regression testing each branch would be a painful, time-consuming process that prevented new features from being worked on – except E1.1, which created an even more costly and risky integration into trunk.
This situation could have been alleviated by the E1, E2, E3, and/or E4 developers directly merging the changes on other branches into their own branch prior to their production release and merge into trunk. For instance, in month 4 the E4 developers might have merged the latest E1 changes, the latest E2 changes, and the final E3 changes into the E4 branch prior to release.
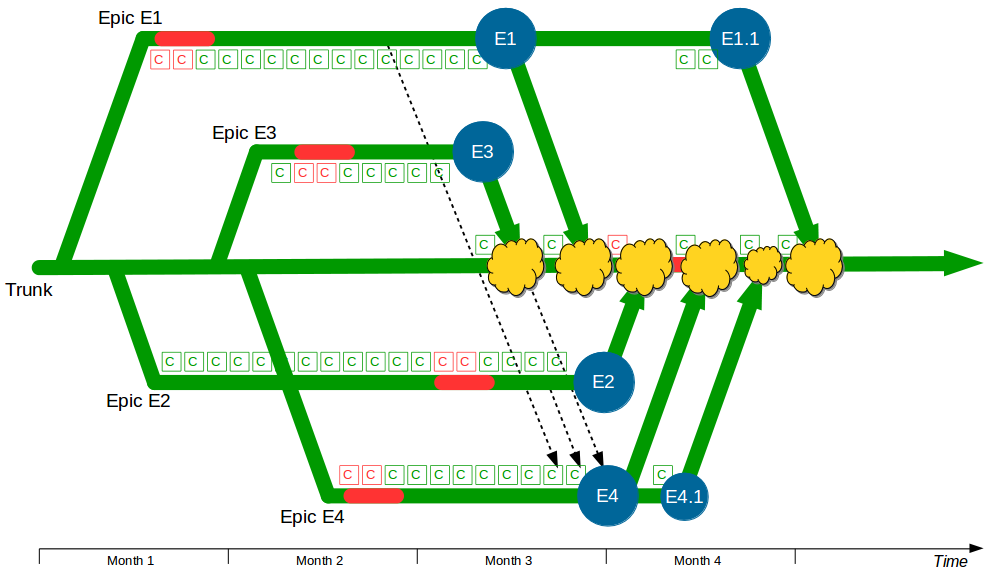
Martin Fowler refers to this process of directly merging between branches as Promiscuous Integration, and promiscuously integrating E1, E2, and E3 into E4 would certainly have reduced the complexity of the eventual trunk + E3 + E1 + E2 + E4 merge. However, newer E1 and E2 changes could still introduce complexity into that merge, and regression testing E4 on trunk would still be necessary.
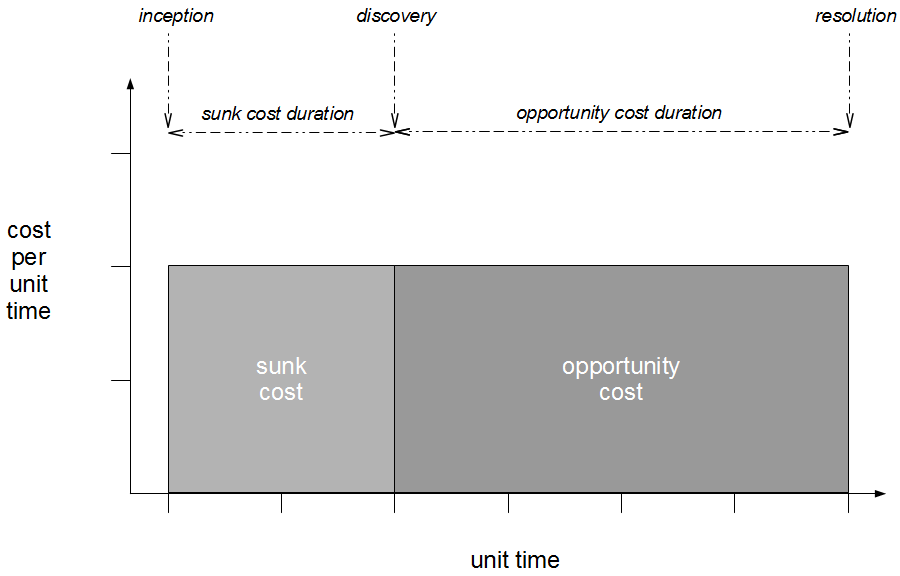
The above example shows how Release Feature Branching inserts an enormously costly and risky integration phase into software delivery. Developer time must be spent managing and merging feature branches into trunk, and with each branch delaying feedback for prolonged periods a complex merge process per branch is inevitable. Tester time must be spent regression testing trunk, and although some merge tools can automatically handle syntactic merge conflicts there remains potential for Semantic Conflicts and subtle errors between features originating from different branches. Promiscuous Integration between branches can reduce merge complexity, but it requires even more developer time devoted to branch management and the need for regression testing on trunk is unchanged.
Since the mid 2000s Release Feature Branching has become increasingly rare due to a greater awareness of its costs. Branching, merging, and regression testing are all non-value adding activities that reduce available time for feature development, and as branches diverge over time there will be a gradual decline in collaboration and codebase quality. This is why it is important to heed the advice of Dave Farley and Jez Humble that “you should never use long-lived, infrequently merged branches as the preferred means of managing the complexity of a large project“.


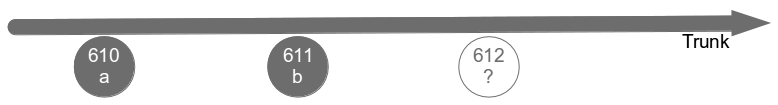{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}