Verify Branch By Abstraction extends Branch By Abstraction to reduce risk
A fundamental requirement of Continuous Delivery is that the codebase must always be in a releasable state, with each successful pipeline commit resulting in an application artifact ready for production use. This means major changes to application architecture are a significant challenge – how can an architecture evolve without impacting the flow of customer value or increasing the risk of production failure?
In the Continuous Delivery book, Dave Farley and Jez Humble strongly advocate Trunk-Based Development and recommend the Branch By Abstraction pattern by Paul Hammant for major architectural changes. Branch By Abstraction refers to the creation of an abstraction layer between the desired changes and the remainder of the application, enabling evolutionary design of the application architecture while preserving the cadence of value delivery.
For example, consider an application consuming a legacy component that we wish to replace with a newer alternative. The scope of this change spans multiple releases, and has the potential to impede the development of other business features.
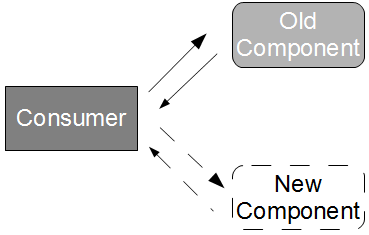
To apply Branch By Abstraction we model an abstraction layer in front of the old and new component entry points, and delegate to the old component at build-time while the new component is under development. When development is complete, we release an application artifact that delegates to the new component and delete the old component.
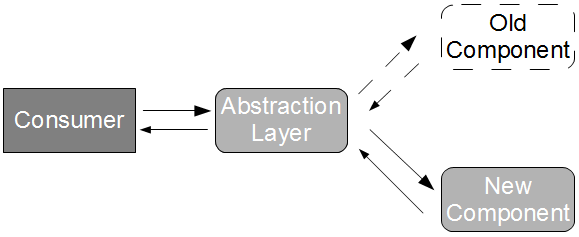
While this form of Branch By Abstraction successfully decouples design lead time from release lead time, there is still an increased risk of production failure when we switch to the new component. Dave and Jez have shown that “shipping semi-complete functionality along with the rest of your application is a good practice because it means you’re always integrating and testing“, but our new component could still cause a production failure. This can be alleviated by introducing a run-time configuration toggle behind the abstraction layer, so that for an agreed period of time we can dynamically revert to the old component in the event of a failure.
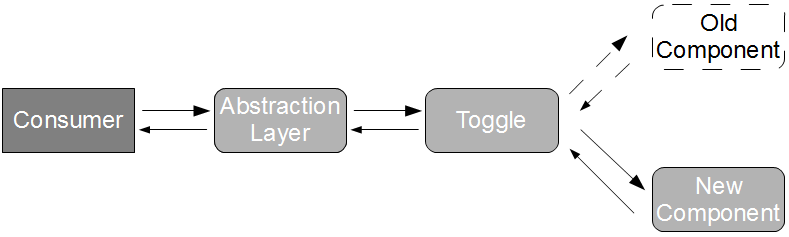
Enhancing Branch By Abstraction with a run-time configuration toggle reduces the cost of failure when switching to the new component, but there remains a heightened probability of failure – although our abstraction layer compels the same behaviour, it cannot guarantee the same implementation. This can be ensured by applying Verify Branch By Abstraction, in which our run-time configuration toggle delegates to a verifying implementation that calls both components with the same inputs and fails fast if they do not produce the same output. This reduces the feedback loop for old and new component incompatibilities, and increases confidence in our evolving architecture.
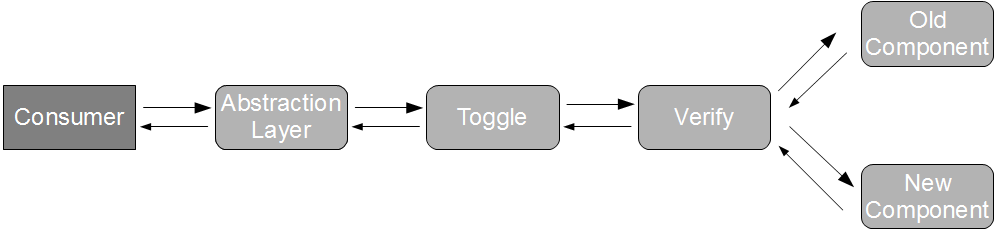
The value of Branch By Abstraction has been summarised by Jez as “your code is working at all times throughout the re-structuring, enabling continuous delivery“, and Verify Branch By Abstraction is an extension that provides risk mitigation. As with its parent pattern, it requires a substantial investment from the development team to accept the increased maintenance costs associated with managing multiple technologies for a period of time, but the preservation of release cadence and reduced risk means that Verify Branch By Abstraction is a valuable Trunk Based Development strategy.

![Economic Batch Size [Reinertsen]](https://www.stevesmith.tech/wp-content/uploads/2013/03/Economic-Batch-Size-Reinertsen.jpg)

Recent Comments