Why is it important to measure operability? What should be the trailing indicators and leading indicators of operability?
TL;DR:
- Reliability means balancing the risk of unavailability with the cost of sustaining availability.
- Availability can be understood as a level of availability, from 99.0% to 99.999%.
- Increasing an availability level incurs up to an order of magnitude more engineering effort.
- An availability target is selected by a product manager based upon the maximum revenue loss they can tolerate for their service.
Introduction
Organisations must have reliable IT applications at the heart of their business if they are to innovate in changing markets. Reliability is defined by Patrick O’Connor and Andre Kleyner in Practical Reliability Engineering as “the probability that [a system] will perform a required function without failure under stated conditions for a stated period of time”. There must be an investment in reliability if propositions are to be rapidly delivered to customers and remain highly available.
Reliability means balancing the risk of application unavailability with the cost of sustaining application availability. Application unavailability will incur opportunity costs related to lower customer revenue, loss of confidence, and reputational damage. On the other hand, sustaining application availability also incurs opportunity costs, as engineering time must be devoted to operational work instead of new product features visible to customers. In Site Reliability Engineering, Betsey Beyer et al state “cost does not increase linearly… an incremental improvement in reliability may cost 100x more than the previous increment”.
Furthermore, the user experience of application availability will be constrained by lower levels of user device availability. For example, a smartphone with 99.0% availability will not allow a user to experience a website with 99.999% availability. 100% availability is never the answer, as the cost is too high and users will not perceive any benefits. Maximising feature delivery will harm availability, maximising availability will harm feature delivery.
Availability targets
Application availability can be understood as an availability target. An availability target represents a desired level of availability, and is usually expressed as a number of nines. Each additional nine of availability represents an order of magnitude more of engineering effort. For example, 99.0% availability means “two nines”, and if its engineering effort is N then 99.9% availability would require 10N in engineering effort.
An availability target should be coupled to product risk. This will ensure a product owner translates their business goals into operational objectives, and empowers their team to strike a balance between application availability and costs. The goal is to improve the operability of an application until its availability target is met, and can be sustained.
For example, consider a Fruits R Us organisation with 3 availability targets for its applications – 99.0% (“two nines”), 99.5% (“two and a half nines”), and 99.9% (“three nines”). The 99.9% availability target allows for a maximum of 0.1% unavailability per month, which in a 30 day month equates to a maximum of 43 mins 12 seconds unavailability. It also requires 10 times more engineering effort to sustain than the 99.0% availability target.
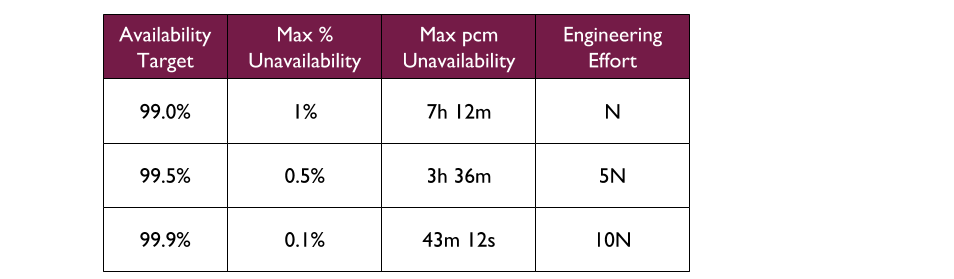
In Site Reliability Engineering, the maximum unavailability per month for an availability target is expressed as an error budget. Error budgets are are a method of formalising the shared ownership and prioritisation of product features versus operational features, and might be used to halt production deployments during periods of sustained unavailability.
Availability target selection
A product owner should select an availability target by comparing their projected revenue impact of application unavailability with the set of possible availability targets. They need to consider if their application is tied directly or indirectly to revenue, their application payment model, what expectations users will have, and what level of service is provided by competitors in the same marketplace.
First, an organisation needs to establish a minimum Cost Of Delay revenue loss for each availability target, on loss of availability. Then a product owner should estimate the Cost Of Delay for their application being unavailable for the duration of each target. The Value Framework by Joshua Arnold et al can be used to estimate the financial impact of the loss of an application:
- Increase Revenue – does the application increase sales levels
- Protect Revenue – does the application sustain current sales levels
- Reduce Costs – does the application reduce current incurred costs
- Avoid Costs – does the application reduce potential for future incurred costs
This will allow a product owner to balance their need for application availability with the opportunity costs associated with consistently meeting that availability level.
For example, at Fruits R Us a set of revenue bands is attached to existing availability targets, based on an analysis of existing revenue streams. The 99.0% availability target is intended for applications where the Cost Of Delay on unavailability is at least £50K in 7h 12m, whereas 99.9% is for unavailability that could cost £1M or more in only 43m 12s.
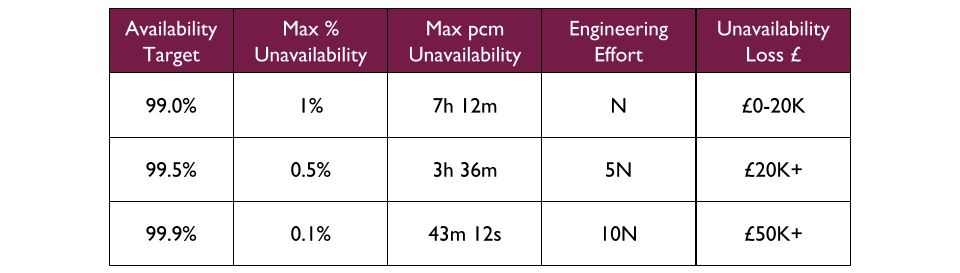
A proposed Bananas application is expected to produce a monthly revenue increase of £40K. It is intended to replace an Apples application, which has an availability target of 99.0% sustained by an average of 8 engineering hours per month. The Bananas product owner believes customers will have heightened reliability expectations due to superior competitor offerings in the marketplace, and that Bananas could lose the £40K revenue increase within 2 hours of unavailability in a month. The 99.0% availability target can fit 2 hours of unavailability into its 7h 12m ceiling, but cannot fit a £40K revenue loss. The 99.5% availability target is selected, and the Bananas product owner knows at 5N engineering effort that 40 engineering hours will be needed per month to invest in operational features.
Acknowledgements
Thanks to Thierry de Pauw for the review