The Version Control Strategies series
- Organisation antipattern – Release Feature Branching
- Organisation pattern – Trunk Based Development
- Organisation antipattern – Integration Feature Branching
- Organisation antipattern – Build Feature Branching
Build Feature Branching is oft-incompatible with Continuous Integration
Build Feature Branching is a version control strategy where developers commit their changes to individual remote branches of a source code repository prior to the shared trunk. Build Feature Branching is possible with centralised Version Control Systems (VCSs) such as Subversion and TFS, but it is normally associated with Distributed Version Control Systems (DVCSs) such as Git and Mercurial – particularly GitHub and GitHub Flow.
In Build Feature Branching Trunk is considered a flawless representation of all previously released work, and new features are developed on short-lived feature branches cut from Trunk. A developer will commit changes to their feature branch, and upon completion those changes are either directly merged into Trunk or reviewed and merged by another developer using a process such as a GitHub Pull Request. Automated tests are then executed on Trunk, testers manually verify the changes, and the new feature is released into production. When a production defect occurs it is fixed on a release branch cut from Trunk and merged back upon production release.
Consider an organisation that provides an online Company Accounts Service, with its codebase maintained by a team practising Build Feature Branching. Initially two features are requested – F1 Computations and F2 Write Offs – so F1 and F2 feature branches are cut from Trunk and developers commit their changes to F1 and F2.

Two more features – F3 Bank Details and F4 Accounting Periods – then begin development, with F3 and F4 feature branches cut from Trunk and developers committing to F3 and F4. F2 is completed and merged into Trunk by a non-F2 developer following a code review, and once testing is signed off on Trunk + F2 it is released into production. The F1 branch grows to encompass a Computations refactoring, which briefly breaks the F1 branch.
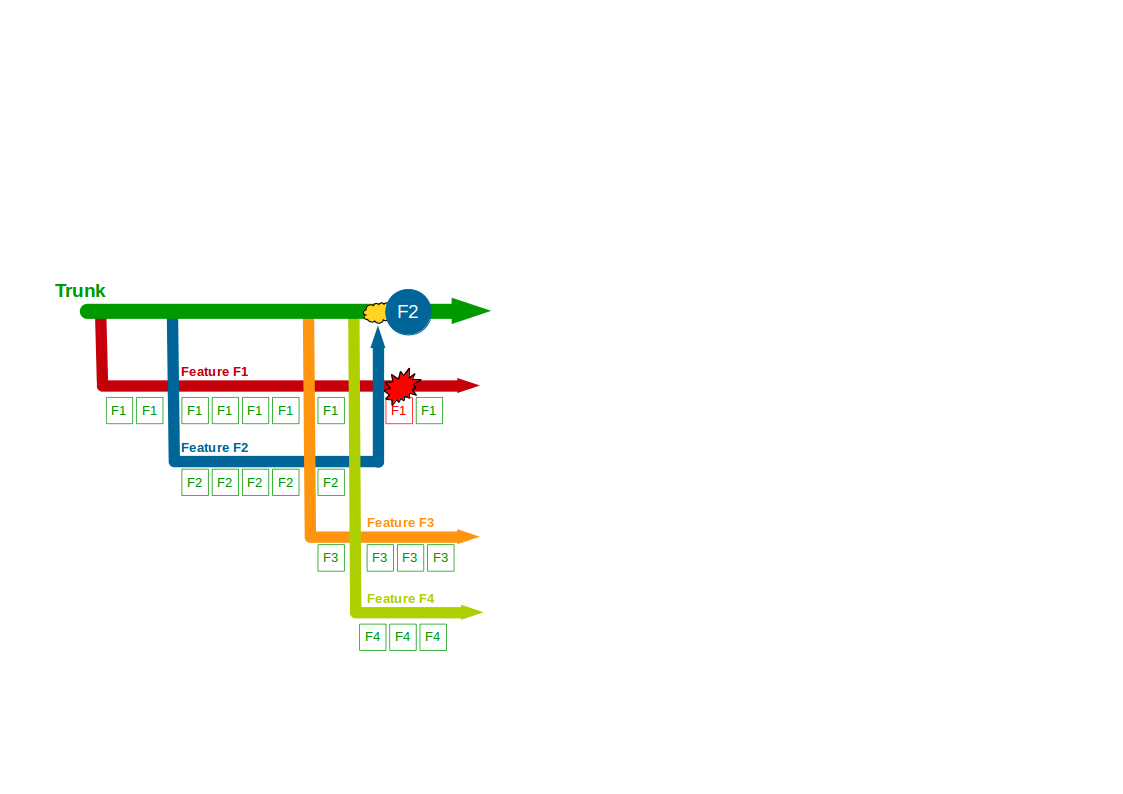
A production defect is found in F2, so a F2.1 fix for Write Offs is made on a release branch cut from Trunk + F2 and merged back when the fix is in production. F3 is deemed complete and merged into Trunk + F2 + F2.1 by a non-F3 developer, and after testing it is released into production. The F1 branch grows further as the Computations refactoring increases in scope, and the F4 branch is temporarily broken by an architectural change to the submissions system for Accounting Periods.
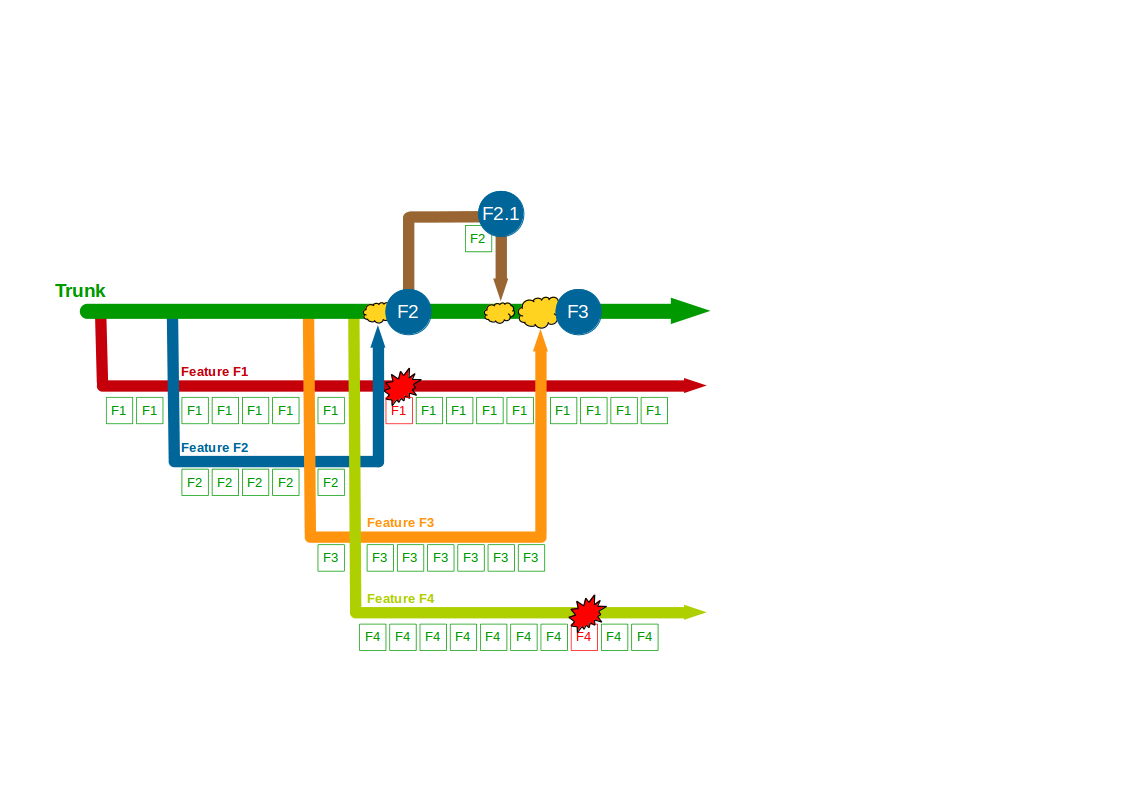
When F1 is completed the amount of modified code means a lengthy code review by a non-F1 developer and some rework are required before F1 can be merged into Trunk + F2 + F2.1 + F3, after which it is successfully tested and released into production. The architectural changes made in F4 also mean a time-consuming code review and merge into Trunk + F2 + F2.1 + F3 + F1 by a non-F4 developer, and after testing F4 goes into production. However, a production defect is then found in F4, and a F4.1 fix for Accounting Periods is made on a release branch and merged into Trunk + F2 + F2.1 + F3 + F1 + F4 once the defect is resolved.
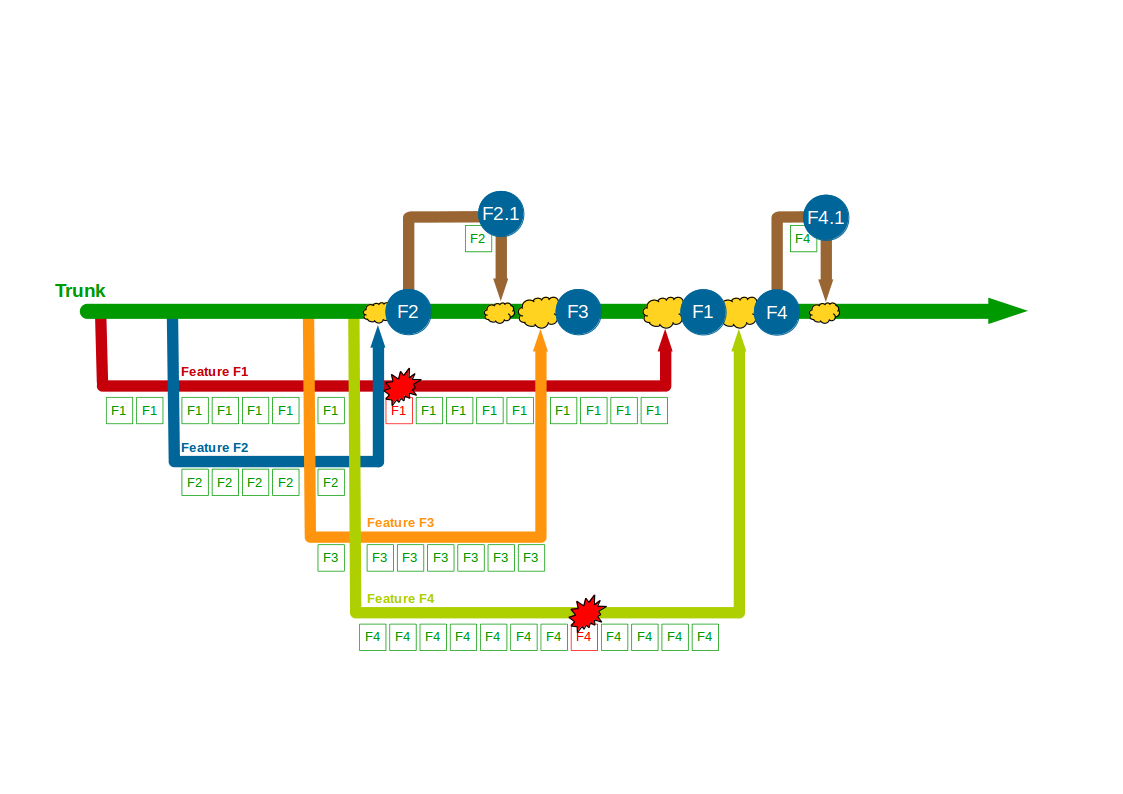
In this example F1, F2, F3, and F4 all enjoy uninterrupted development on their own feature branches. The emphasis upon short-lived feature branches reduces merge complexity into Trunk, and the use of code reviews lowers the probability of Trunk build failures. However, the F1 and F4 feature branches grow unchecked until they both require a complex, risky merge into Trunk.
The Company Accounts Service team might have used Promiscuous Integration to reduce the complexity of merging each feature branch into Trunk, but that does not prevent the same code deviating on different branches. For example, integrating F2 and F3 into F1 and F4 would simplify merging F1 and F4 into Trunk later on, but it would not restrain F1 and F4 from generating Semantic Conflicts if they both modified the same code.
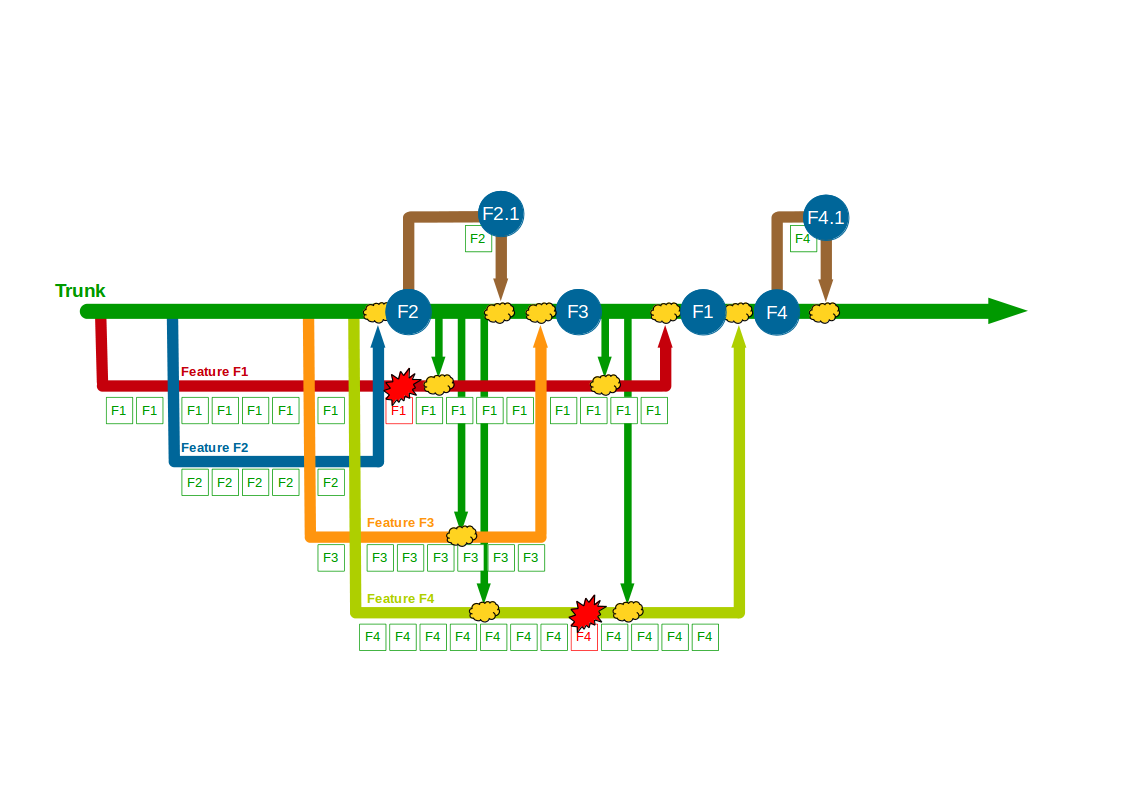
This example shows how Build Feature Branching typically inserts a costly integration phase into software delivery. Short-lived feature branches with Promiscuous Integration should ensure minimal integration costs, but the reality is feature branch duration is limited only by developer discipline – and even with the best of intentions that discipline is all too easily lost. A feature branch might be intended to last only for a day, but all too often it will grow to include bug fixes, usability tweaks, and/or refactorings until it has lasted longer than expected and requires a complex merge into Trunk. This is why Build Feature Branching is normally incompatible with Continuous Integration, which requires every team member to integrate and test their changes on Trunk on at least a daily basis. It is highly unlikely every member of a Build Feature Branching team will merge to Trunk daily as it is too easy to go astray, and while using a build server to continuously verify branch integrity is a good step it does not equate to shared feedback on the whole system.
Build Feature Branching advocates that the developer of a feature branch should have their changes reviewed and merged into Trunk by another developer, and this process is well-managed by tools such as GitHub Pull Requests. However, each code review represents a handover period full of opportunities for delay – the developer might wait for reviewer availability, the reviewer might wait for developer context, the developer might wait for reviewer feedback, and/or the reviewer might wait for developer rework. As Allan Kelly has remarked “code reviews lose their efficacy when they are not conducted promptly“, and when a code review is slow the feature branch grows stale and Trunk merge complexity increases. A better technique to adopt would be Pair Programming, which is a form of continuous code review with minimal rework.
Asking developers working on orthogonal tasks to share responsibility for integrating a feature into Trunk dilutes responsibility. When one developer has authority for a feature branch and another is responsible for its Trunk merge both individuals will naturally feel less responsible for the overall outcome, and less motivated to obtain rapid feedback on the feature. It is for this reason Build Feature Branching often leads to what Jim Shore refers to as Asynchronous Integration, where the developer of a feature branch starts work on the next feature immediately after asking for a review, as opposed to waiting for a successful review and Trunk build. In the short-term Asynchronous Integration leads to more costly build failures, as the original developer must interrupt their new feature and context switch back to the old feature to resolve a Trunk build failure. In the long-term it results in a slower Trunk build, as a slow build is more tolerable when it is monitored asynchronously. Developers will resist running a full build locally, developers will then checkin less often, and builds will gradually slowdown until the entire team grinds to a halt. A better solution is for developers to adopt Synchronous Integration in spite of Build Feature Branching, and by waiting on Trunk builds they will be compelled to optimise it using techniques such as acceptance test parallelisation.
Build Feature Branching works well for open-source projects where a small team of experienced developers must integrate changes from a disparate group of contributors, and the need to mitigate different timezones and different levels of expertise outweighs the need for Continuous Integration. However, for commercial software development Build Feature Branching fits the Wikipedia definition of an antipattern – “a common response to a recurring problem that is usually ineffective and risks being highly counterproductive“. A small, experienced team practising Build Feature Branching could theoretically accomplish Continuous Integration given a well-structured architecture and a predictable flow of features, but it would be unusual. For the vast majority of co-located teams working on commercial software Build Feature Branching is a costly practice that discourages collaboration, inhibits refactoring, and by implicitly sacrificing Continuous Integration acts as a significant impediment to Continuous Delivery. As Paul Hammant has said, “you should not make branches for features regardless of how long they are going to take“.
There’s nothing wrong with feature branches as such. The real antipattern here is the practice of having centralised continuous integration and effectively having no continuous integration whatsoever as soon as you branch. These are three huge problems, not just one. Having a central branch means having an organizational bottleneck (problem #1) and it means that the only way to get stuff done is to actually branch. Branching for extended periods without continuous integration means software is more buggy when it finally gets merged (problem #2). This in turn means bigger, more buggy, and relatively big deltas get integrated. Testing effort scales exponentially to the amount of change, so centralised testing on large deltas is the most expensive way to do it. (problem #3). So, by not doing distributed version management and distributed continuous integration you are creating more buggy software and are bloating your testing cost. This in a nutshell is why big companies suck at creating software. The bigger they become, the larger their problems.
If you don’t believe me go stare at the commit statistics for the linux kernel on Github for a while. Fastest evolving software project on the planet that runs circles around anything corporate. Millions of lines of code, hundreds of thousands affected with each point release. Regular as clockwork releases where everything that lands is a feature branch.
What linux did was distribute the integration effort away from the main release branch. By the time something lands there, 99% of the testing work has already been done. This is both more effective and more scalable and frankly the only way you can do a project the size of the linux kernel. Enterprises doing mock waterfall disguised as ‘agile’ can learn a thing or two from linux. Having a centralised continuous integration environment means you just serialized the entire company around a single bottleneck that ends up blocking production releases. The larger your organization, the bigger the problem is, the more ceremony you get around actually doing a release, and the less agile you become. Feature branches are the solution, not the problem. But you need to do the testing before you land them (or in Linux terms before somebody will dignify your efforts with a merge). Reversing the control here is essential. You don’t push changes, they get pulled if and only if they are actually good enough. If you are pushing feature branches, you are doing it wrong.
Hi Jilles
Thanks for commenting.
I disagree entirely with the notion that centralised Continuous Integration is an antipattern. By definition Continuous Integration is centralised – it is not a tool or a build server, it is a shared mindset in which all developers on a team commit to trunk (call it master, if you wish) at least once a day.
As I said above, continuously building changes on a branch to verify its integrity is a good idea. But it is not Continuous Integration as you are integrating with any other branches.
According to the Theory Of Constraints https://en.wikipedia.org/wiki/Theory_of_constraints, there is always a bottleneck and it should be exploited until it moves. A central branch does not have to be a bottleneck. If for example a team invests in Trunk Based Development http://www.alwaysagileconsulting.com/organisation-pattern-trunk-based-development/ then changes can flow from Trunk out to production with minimal delay.
Yes.
I’m afraid not, plenty of companies I’ve worked at or know of were/are delivering high quality software with centralised Version Control Systems. For example, Google uses Perforce http://paulhammant.com/2013/05/06/googles-scaled-trunk-based-development/.
If only life was so simple! Continuous Delivery flushes out a lot of challenges in an organisation, and version control is one but certainly not the only one.
As I mentioned above, Build Feature Branching works well for open-source projects where a small team of experienced developers must integrate changes from a disparate group of contributors, and the need to mitigate different timezones and different levels of expertise outweighs the need for Continuous Integration. Linux was one of the examples I had in mind when I wrote that. By testing feature branches prior to merging into master, there is increased confidence it will work on master. However, when those changes are merged onto master I’m sure the core Linux team run some tests on that change – and those tests a) may duplicate earlier efforts on the branch and b) might fail if the branch was not synced with the latest changes on master. This is not inherently a bad thing – it is a tradeoff made by Linux and it works well for them. What works for a worldwide open-source distributed project with different contributors of varying skills levels might not work for commercial software development by a co-located team.
Cheers
Steve
Google probably also use branches and they don’t have separate repositories for each product. So, if you break the build in Google, you inconvenience the entire company (thousands of developers). The only way this works is that they test before they put stuff in, not after. They are also quite smart about making this process really fast. This is the key thing.Tthis only works if the stuff being integrated has been tested to the point where it is unlikely to break anything. So, if you are only running integration tests on your master branch, people’ll end up breaking the build quite often unless you have a very small team. If you do this at scale it becomes a bottleneck for getting change in.
The thing with open source projects is that many of the successful ones are so complicated in terms of people involved and amount of changes happening that they’ve evolved strategies for operating better out of necessity. The linux kernel receives contributions from thousands of people spread over hundreds of different organizations. There’s no such thing as the Linux team. The way it works instead is that changes get developed and tested by small groups of individuals and contributed when they are ready and already fully integrated, revied, etc.. This is much less work than if everyone were to push their untested changes on a master branch. It distributes the testing effort: many small changes tested in isolation is much less effort than testing the same amount of change altogether.
The amount of change in the Linux kernel is way beyond what a testing team of any reasonble size would be able to deal with. It’s quite beyond the point where having a master branch + CI actually still is managable. Linus Torvalds moved away from that in the late nineties already.
This is for 24 June 2015-24 July 2015 (1 month) according to Github.
“Excluding merges, 511 authors have pushed 1,562 commits to master and 1,573 commits to all branches. On master, 8,797 files have changed and there have been 955,179 additions and 220,501 deletions.”
That’s a million lines of code changed. In a month. In what is supposedly a quiet period due to summer holidays. Where it reads commits, think pull requests. These are pre-tested and integrated changes that are being pulled into master. En new kernel gets released every 2-3 months.
Having a single central branch + CI is something you can get away with with small teams and relatively insignificant amounts of commits. Beyond that enterprises compensates with vast expenses on tools, development bureuacracy (aka agile), and consultancy. I’ve been in such companies that ticked all the boxes in terms of CI, agile, etc. and still made a mess of it. If you’ve ever experienced a commit freeze or otherwise been told to not commit to master, that’s a clear sign that the process just stopped scaling. The next step up from that is breaking down into multiple projects managed by smaller teams or using a distributed vcs + CI strategy.
Hi Jilles,
On my project we have a team 150+ developers we are using central brunch and we are often experiences code freezes because of a red build. We think about how could be improve our process and we tried to work in feature brunches, but result was exactly like it was described in a post.
As I understand you suggests to run feature specific tests before pushing to master? But what if we are changing functionality that is already in master? What if someone else is changing it in different feature?
The solution could be to have suite of tests in master and running them after merge before pushing to master. But even after doing this there is still a chance that something will go wrong in master.
So, using feature branches development process is usually smooth, but pushing and merging is a pain.
May be you could describe in details how could we avoid it?
Hi Vadym
Thanks for commenting. I will leave Jilles to answer you, but I would say broken builds are often a smell of other issues e.g. developers not running tests locally, intermittent tests, slow build, etc. One thing that could definitely help you is a post-build auto-revert on failure.
Steve
Google does trunk-based development. However, committing at Google isn’t that simple – a commit runs all tests on the committed code itself before pushing the changes to trunk. And you don’t get to even attempt the commit if reviewers aren’t happy with the coverage of your tests – what reviewers are after is not 100% branch or line coverage, but thoughtfully testing your changes in any reasonable way.
And yes. It only happens once in a blue moon, but sometimes Google’s codebase is broken for days, and it’s visible only internally.
Hi Anon
Thanks for commenting. I’m aware of how Google does Trunk Based Development, and it’s very interesting. Code review and testing pre-build actions are fairly common, it’s good to see them used at scale.
An assessment of quality of testing, rather than quantity is absolutely the way to go.
Steve
Just realized I should be a bit more specific. “Broken” above doesn’t mean nothing works. It just means a specific change, tested in one very specific context before being committed, happens to cause some minor issue elsewhere, somewhere the automated test tools happened to miss something. That’s why it’s also so rare. It’s not like suddenly all of Google stops doing anything. And precisely the low severity is what makes it unnecessary to come up with a fix too fast, at the cost of the quality of the fix.
I like the model where unfinished features are merged in the central branch by small increments, but put behind flags to make sure they’re not getting into production until the work is done. It mitigates the risks you’ve been mentioning.
Of course that works only on products that aren’t too sensitive when it comes to legal and security (since small increments could compromise these).
I also don’t know how much it scales. I believe Firefox, WebKit and Blink use that model. And I experienced it when working on the new Guardian website (open source on GitHub: http://github.com/guardian/frontend).
Hi Kaelig
Thanks for commenting. Feature Toggles work extremely well, and as I mentioned they can provide operational and business benefits as well.
I’ve used Trunk Based Development with Feature Toggles on a financial exchange and UK government tax services. Legal and security concerns can be mitigated through smoke testing and static analysis.
Steve
I agree with what you are saying if a CI build is executed against the head of a feature branch. However, this is not the case in my experience – a Pull Request will create a new branch on the Git server which contains the result of merging the feature branch onto the target branch. That hypothetical merge is what gets built by the CI server. With a Github remote you use a refspec of “+:refs/pull/*/merge” in order to pull these branches. This approach, combined with short-lived feature branches (under one day) and feature toggles, provides the best of both worlds IMO.
Hi Nathan
Thanks for commenting. Are you referring to using +:refs/pull/*/merge to run a continuous build server against pull requests, prior to their merge onto Trunk? If so I mentioned that above, I see it as a useful practice but it falls far short of Continuous Integration
Thanks
Steve
Sorry, I skimmed past that. Our builds spin up an entire stack (eg, Postgres, RabbitMQ plus our app) using Docker compose and run the functional test suite so there is no disadvantage compared to merging first. This is feasible because the apps are microservices with relatively small regression test suites (just 60 or so tests) and the entire build, including Sonar preview analysis takes around 5 minutes.
In my experience, what has helped considerably, is keeping each branch as close to the Trunk as possible.
What has worked for us is to encourage the discipline of Forward Integration from the Trunk to all open branches after each release to production, and resolve any merge conflicts that arise on the spot.
So what you have is frequent, small updates instead of infrequent, large, headache-inducing changes.
Ideally, the only difference between the Trunk and the Feature Branch should be the Features that that branch was created for.
Like the image below, but with Development representing multiple Feature branches that are merged back to the trunk at different times:
source: https://msdn.microsoft.com/en-us/library/ee782536.aspx
Hi Duanne
Thanks for commenting. As I said above Promiscuous Integration can help reduce merge complexity in Build Feature Branching. However, there remain a number of issues using this branching model – the potential for design divergence, the likelihood of Asynchronous Integration, the improbability of Continuous Integration.
It can work well in a small, experienced team but it often fails when those conditions are not met. It certainly does not scale.
Steve
Feature toggles can be useful, but they can introduce their own code smell. They are nice to turn off a feature in a UI (Web or Thick client), but when they are applied to shared components or libraries, they can create significant duplication of code in massive if-else blocks.
Also, feature toggles can suffer from bit rot. I have worked on a system with some elegant implementations of feature toggles in the infrastructure, including tools to change on the fly and APIs for toggle status testing. However, when these feature toggle are left too long, you can have toggle tests nested within toggle tests within toggle tests.
Developers all too often will turn their feature on and forget about it, when it would be more appropriate to come back at some later time after the feature has soaked, and clean up the code. Nothing in this branch model pushes developers to go back and clean up their code, more often than not they are off building the next whiz-bang feature and couldn’t be bothered.
Hi Chris
Thanks for commenting.
Yes, feature toggles should have an expiry date. I do not ascribe to the Etsy or Facebook model of retaining them for prolonged periods of time – beyond development I would use a toggle for Canary Releasing a new production release or Dark Launching a new feature, then retire it afterwards. I have used Feature Toggles for 2-6 weeks, Branch By Abstraction for 3-4 months, and Strangler Application for 1-2 years in the past.
Developers running off to run on the next shiny thing is not a just a problem with toggles. I like the idea of taking the Done Means Released principle of Continuous Delivery and extending it to Done Means Launched, or even Done Means Retired.
Thanks
Steve