Passive Disaster Recovery is Risk Management Theatre
When an IT organisation is vulnerable to a negative Black Swan – an extremely low probability, extremely high cost event causing ruinous financial loss – a traditional countermeasure to minimise downtime and opportunity costs is Passive Disaster Recovery. This is where a secondary production environment is established in a separate geographic location to the primary production environment, with every product increment released into Production and Disaster Recovery retained in a cold standby state.
For example, consider an organisation hosting version v1040 of a customer-facing service in its Production environment. In the event of a catastrophic failure, customers should be immediately routed to the Disaster Recovery environment and receive the same quality of service.
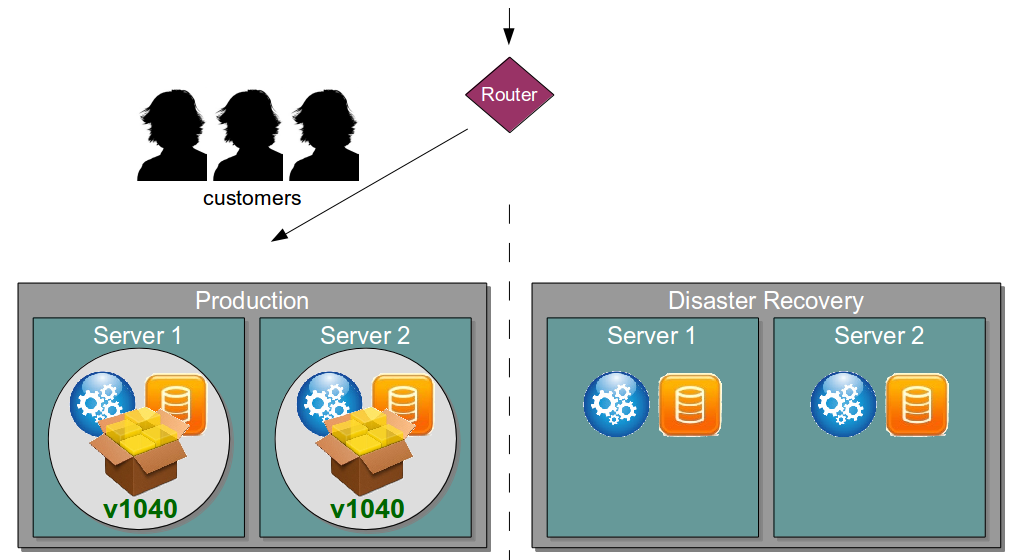
Regardless of physical/virtual hosting and manual/automated infrastructure provisioning, Passive Disaster Recovery is predicated upon the fundamentally flawed assumption that active and passive environments will be identical at any given point in time. Over time the unused Disaster Recovery environment will suffer from hardware, infrastructure, configuration, and software drift until it consists of Snowflake Servers that will likely require significant manual intervention if and when Disaster Recovery is activated. With negative Black Swan opportunity costs incurred at a rapid pace the entire future of the organisation might be placed in jeopardy.
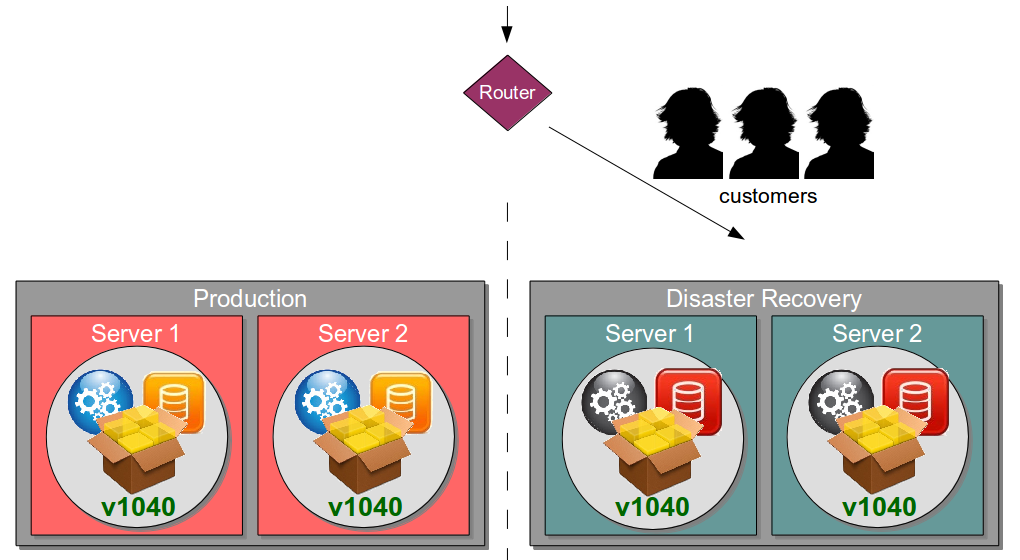
Passive Disaster Recovery remains common due to an industry-wide underestimation of negative Black Swan events. It is easier for an individual or an organisation to appreciate the extremely low probability of a disastrous business event rather than the extremely high opportunity cost, and as a result a Disaster Recovery environment tends to be procured when a business project begins and left to decay into Risk Management Theatre when the capex funding ends.
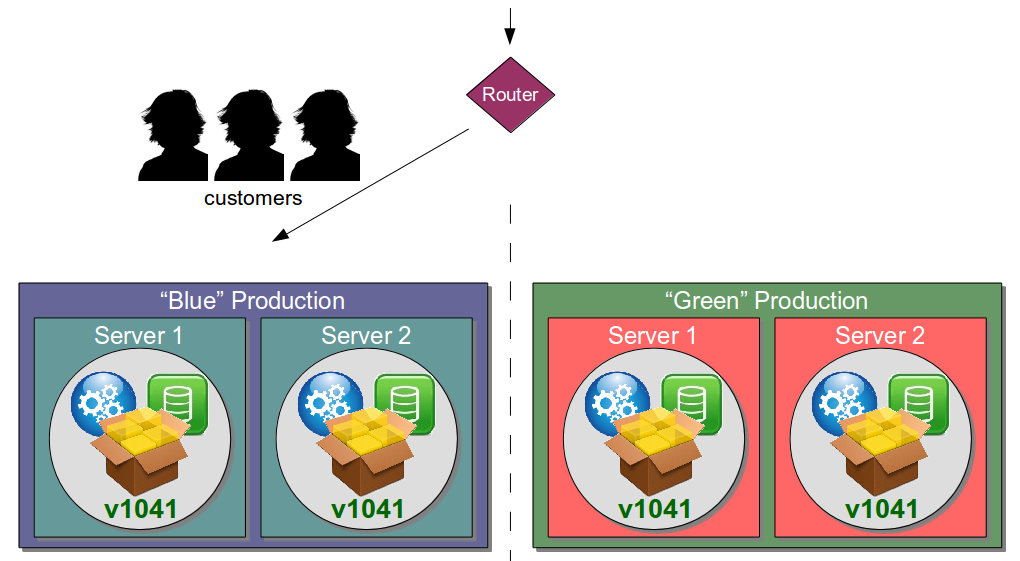
Continuous Delivery advocates a radically different approach to Disaster Recovery as it is explicitly focussed upon reducing the time, risk, and opportunity cost of delivering high quality services. One of its principles is Bring The Pain Forward – increasing the cadence of high cost, low frequency events to drive down transaction costs – and applying it to Disaster Recovery means moving from passive to active standby via Blue Green Releases and rotating production responsibility between two near-identical environments.
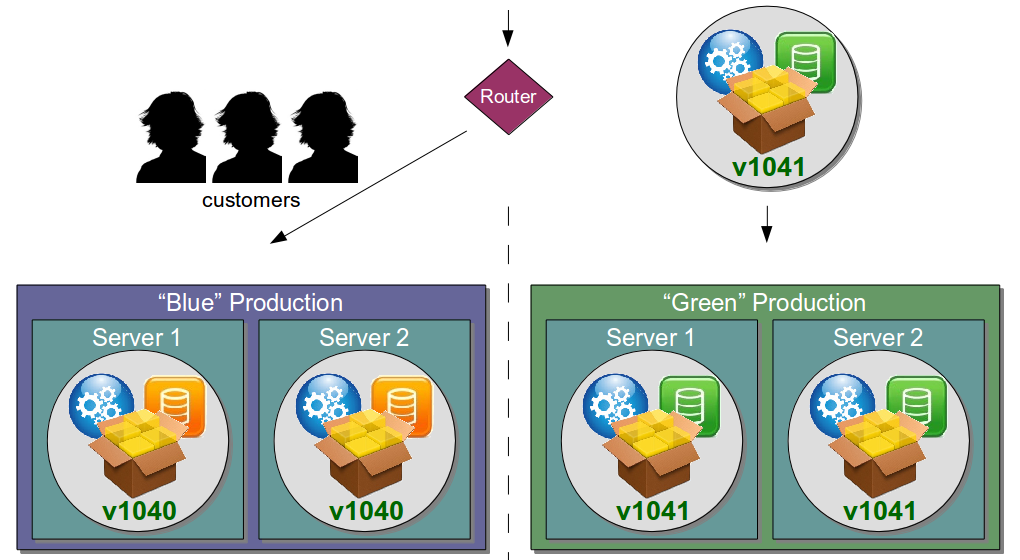
In the above diagram, the Blue production environment is currently hosting v1040 and the Green environment is being upgraded with v1041. Once v1041 passes its automated smoke tests and manual exploratory tests it is signed off and customers are seamlessly rerouted from Blue to Green. A short period of time afterwards Blue is upgraded in the background and awaits the next production release.
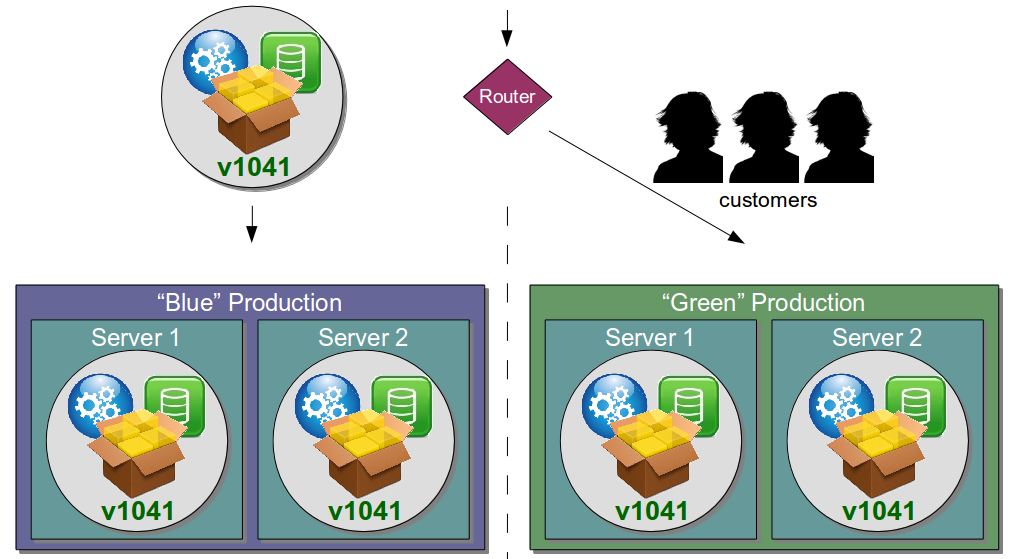
As well as enabling zero downtime releases and a cheap rollback mechanism, Blue Green Releases provides an effective Disaster Recovery strategy as the standby production environment is always active and in a known good state. If the Green environment suffers a complete outage customers can be switched to the Blue environment with complete confidence, and vice versa.
By practicing Blue Green Releases an organisation is effectively rehearsing its Disaster Recovery strategy on every production release, and this can lead to advanced practices such as Chaos Engineering , Fault Injection , and Game Days. It requires a continuous investment in hardware and infrastructure, but it will reduce exposure to negative Black Swans and may even offer a strategic advantage over competitors.