What is Continuous Delivery, and how could it help your organisation?
Continuous Delivery is often cited by organisations with a high performance IT capability, yet it is difficult to find a concise explanation. Executives and managers want to understand its business case, and practitioners want to understand its impact.
Introduction
“Software is eating the world” – Marc Andreessen
If there is one constant in the 21st Century, it is the ever-accelerating rate of technology change. British Gas manages 75,000 thermostats online, Tesla delivers over-the-air fixes to 29,000 cars, and with the Deloitte Shift Index reporting the last 50 years have seen the life expectancy of a Fortune 500 company decline from 75 years to 15 years it is evident the business world has been permanently disrupted by the ubiquity of software. Every business is an IT business now.
If an organisation wants a competitive advantage today it must strategically position IT at the core of its business to rapidly deliver new capabilities and respond to customer demands faster. If successful the rewards are great, as shown by the 2014 State Of DevOps Report declaring organisations with a high performance IT capability were twice as likely to exceed profitability, market share, and productivity goals. However, in many organisations IT has historically been a cost centre used solely for efficiency gains, and as a result years of underinvestment in software delivery must now be rectified.
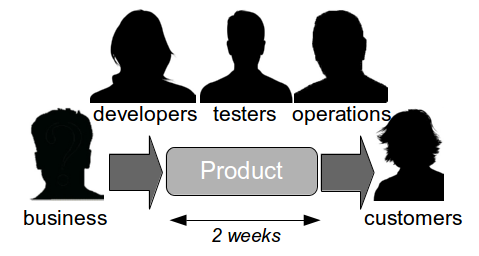
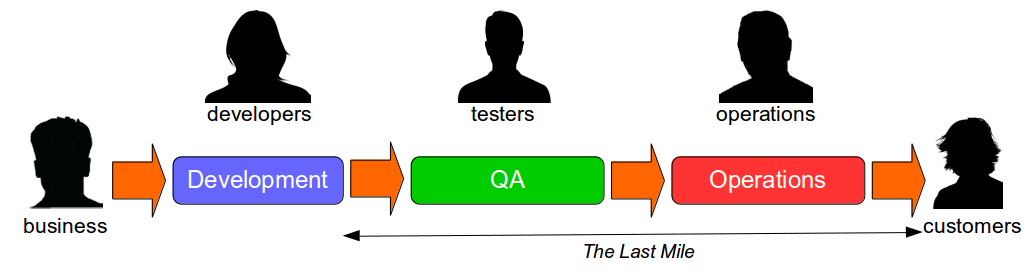
The Last Mile
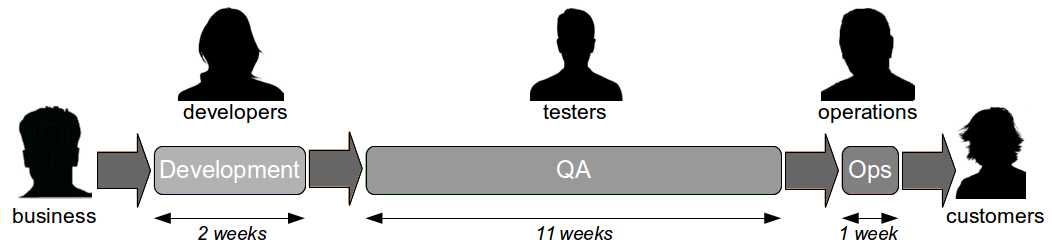
The Last Mile is a term used in IT to describe the value stream in an organisation from development to production, and was originally used in the telecoms industry to describe broadband provisioning from the telephone exchange to the customer premises. In IT the Last Mile is traditionally formed of discrete sequential phases, with work managed via a phase-gate project process.
In telecoms a long Last Mile to the customer means a slower, inferior service and IT is no different – many quality problems occur in the Last Mile, and a longer time to market means slower customer feedback and increased opportunity costs. Unfortunately many organisations have not invested in the Last Mile for years and consequently rely upon a manual release process with developers, testers, system administrators, and database administrators occupied by the following tasks:
- Manual configuration – system administrators manually configure releases, causing runtime application errors
- Manual infrastructure – system administrators manually provision servers and networks, introducing environmental errors
- Manual testing – testers manually regression test releases without production reference data, leading to slow and inaccurate feedback
- Manual database management – database administrators manually apply unversioned database scripts, resulting in faulty and/or nonperformant changes
- Manual operations – systems administrators manually deploy, start, and stop releases, increasing potential for human error
- Manual monitoring – system administrators manually configure operational checks, leading to unreliable alerts
- Manual rollback – systems administrators manually unwind releases upon failure, leaving an inconsistent system state
- Manual audit – testers, database administrators, and systems administrators manually log their actions, producing an inaccurate audit trail
Such a release process is likely to be controlled by a heavyweight change management process, with extensive documentation required and collaboration between teams restricted to a ticketing system. Production releases will take hours or even days, and will be conducted out of business hours due to fear of failure. This results in a stressful, infrequent release process that increases costs and prevents organisations from delivering features to customers on predictable timelines.
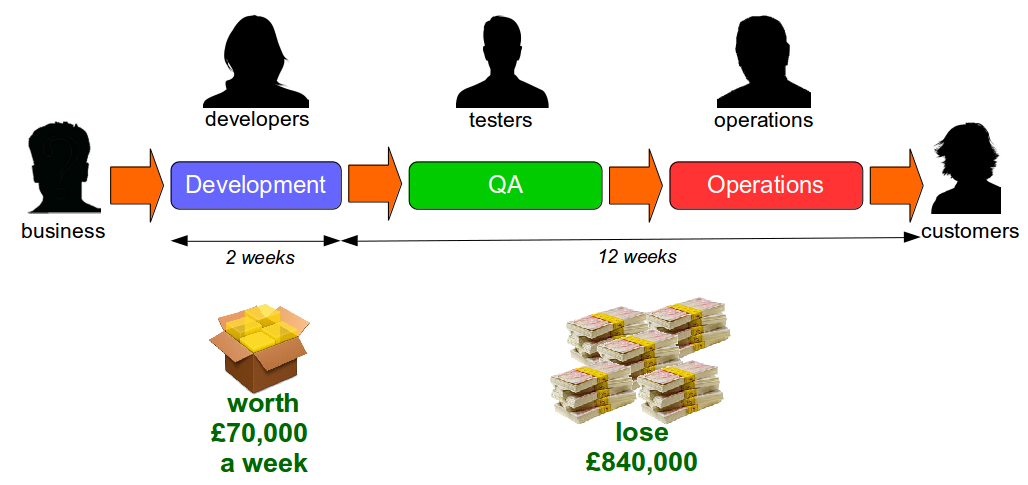
For example, consider an organisation with fortnightly iterations and quarterly production releases. If a product increment is estimated to generate £70,000 per week and is not released for 3 months of 28 days it will incur an opportunity cost of £840,000. In this scenario it is unlikely the Last Mile activities performed would outweigh the opportunity cost.
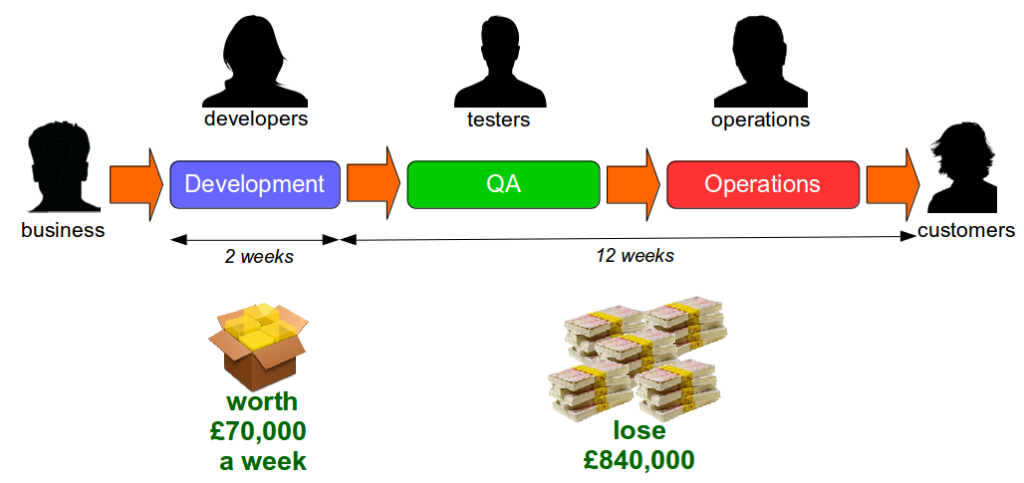
The IT capability of an organisation can be measured by its cycle time, which is the average lead time from development to production. This is sometimes framed as the Poppendieck question:
“How long would it take your organisation to deploy a change that involves just one single line of code?” Mary Poppendieck
A low cycle time can furnish an organisation with a short, repeatable, and reliable Last Mile that represents a strategic advantage over the competition – and Continuous Delivery is the means to accomplish that goal.
Continuous Delivery
Inspired by the first principle of the Agile Manifesto stating “our highest priority is to satisfy the customer through early and continuous delivery of valuable software“, Continuous Delivery is a set of holistic principles and practices that advocate automating a deployment pipeline to rapidly and reliably release software into production. Creating a Continuous Delivery pipeline enables smaller, more frequent production releases that show the business what customers want – and do not want – much faster, reducing opportunity costs and increasing product revenues.
The seminal book “Continuous Delivery” by Dave Farley and Jez Humble describes how Continuous Delivery is composed of the following principles:
| Principle |
Description |
| Repeatable Reliable Process |
Use the same deterministic release mechanism in all environments |
| Automate Almost Everything |
Automate as much of the release workflow as possible |
| Keep Everything In Version Control |
Version control code, config, schemas, infrastructure, etc. |
| Build Quality In |
Develop and test work items in a single continuous activity |
| Bring The Pain Forward |
Increase cadence of infrequent, costly events to reduce errors |
| Done Means Released |
Do not consider a feature complete until it is in production |
| Everybody Is Responsible |
Align individuals and teams with the release process |
| Continuous Improvement |
Continuously improve the people and technology involved |
It is important to note that only the first 3 of these principles are technology-focussed, which is an early indication of the impact of organisational structures and communication pathways upon Continuous Delivery.
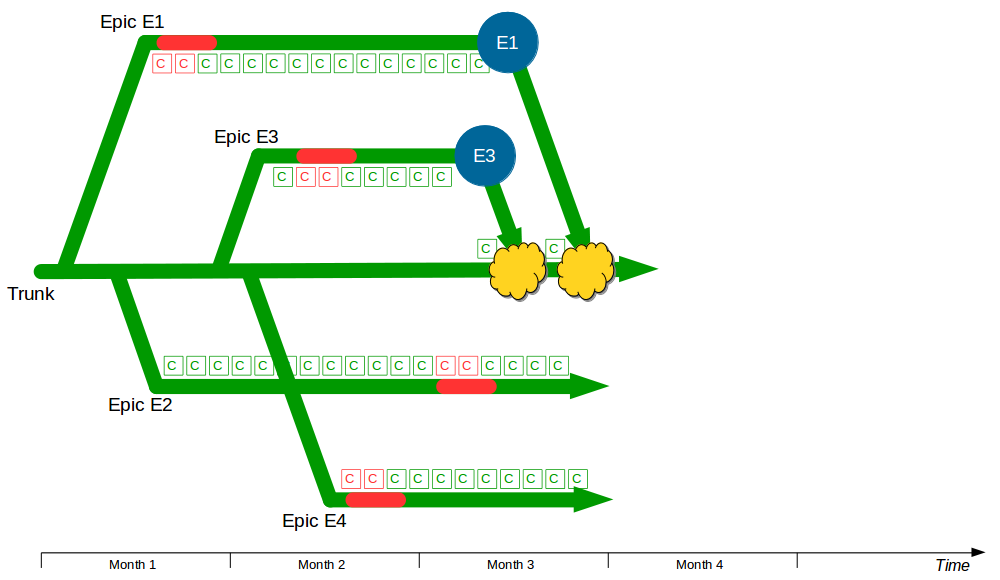
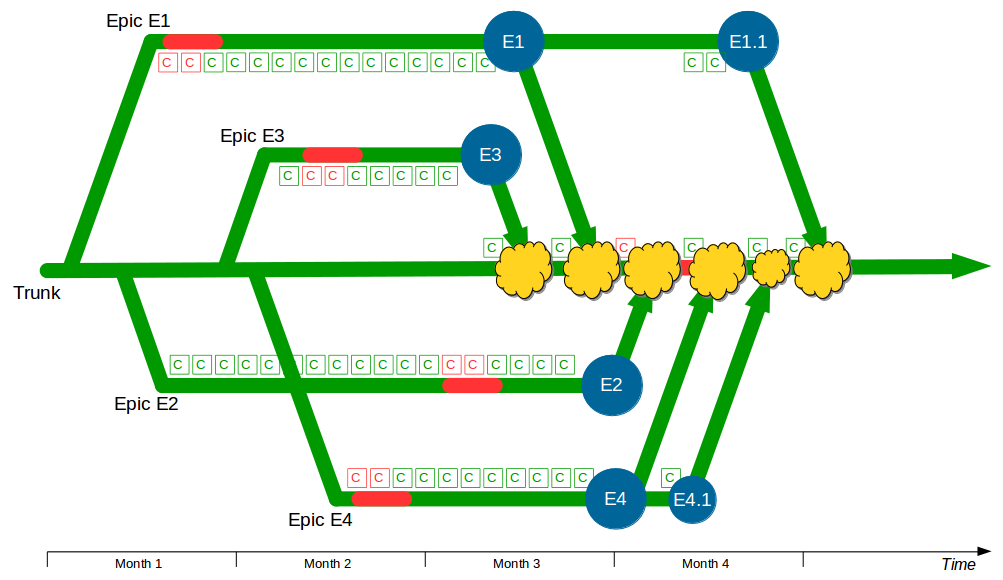
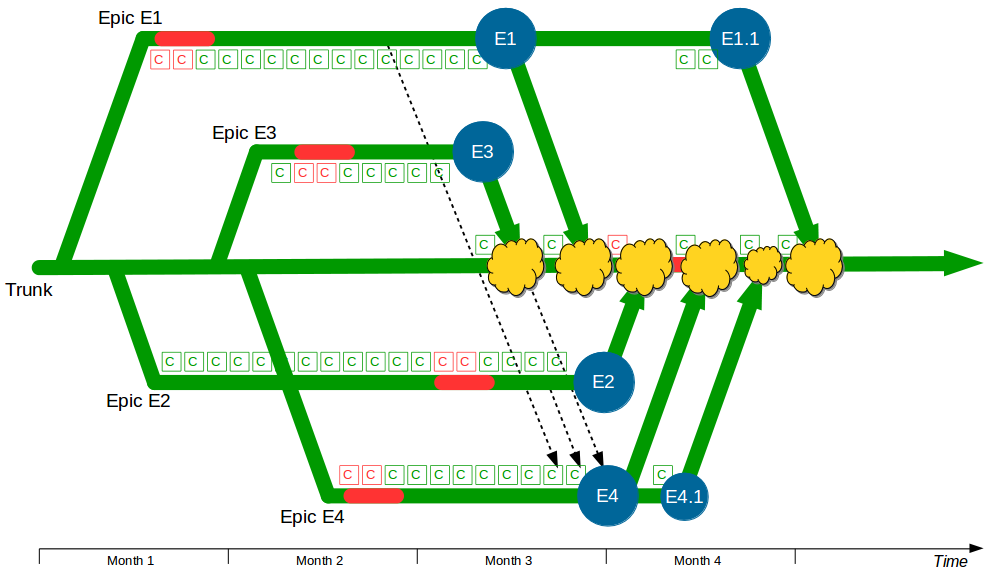
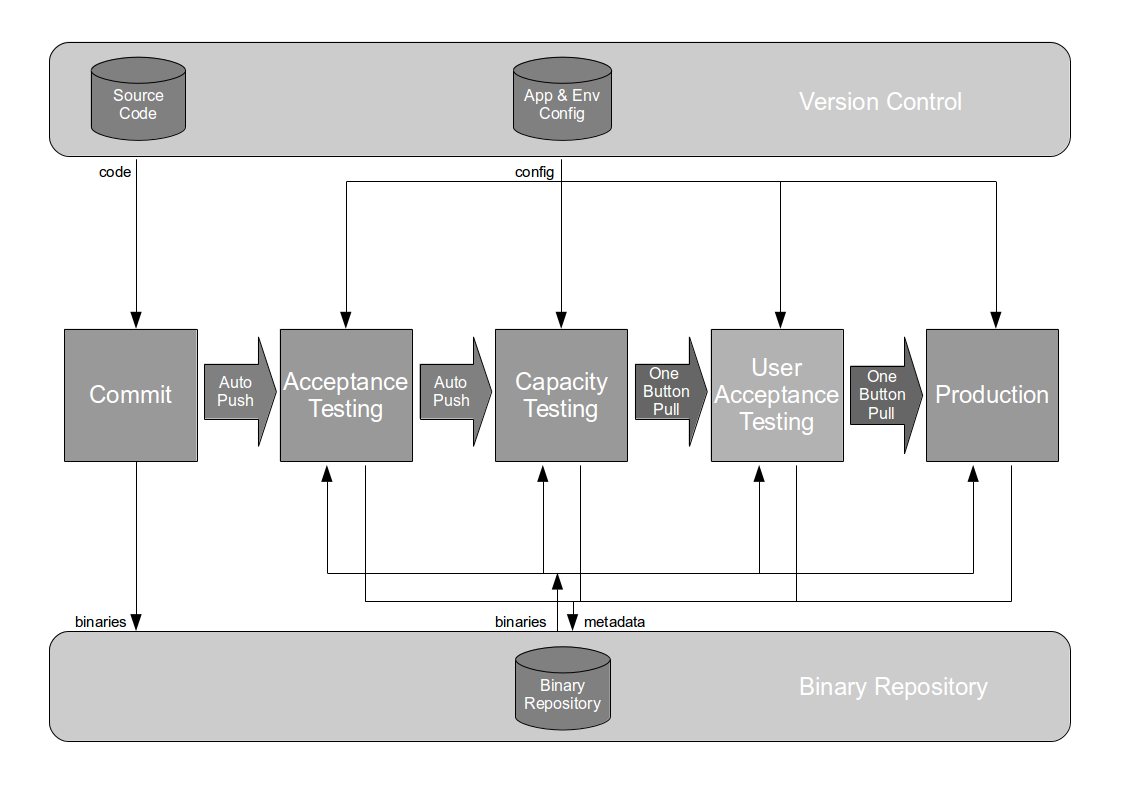
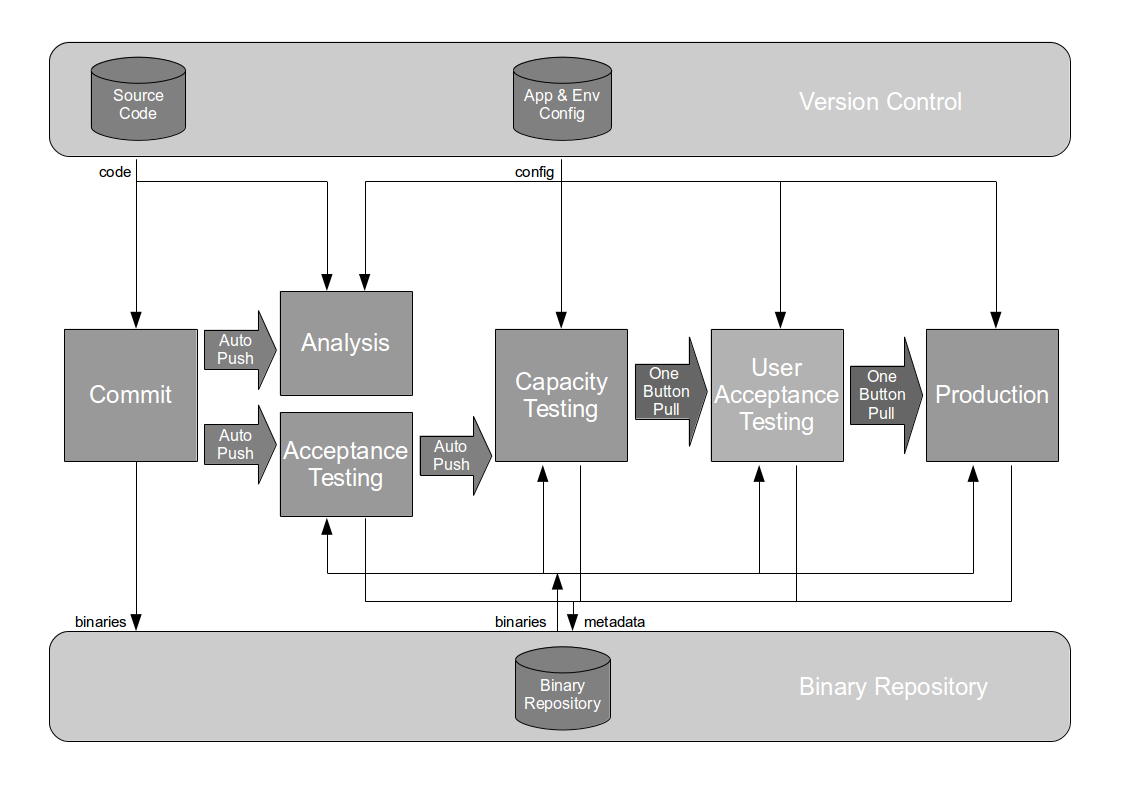
The Deployment Pipeline
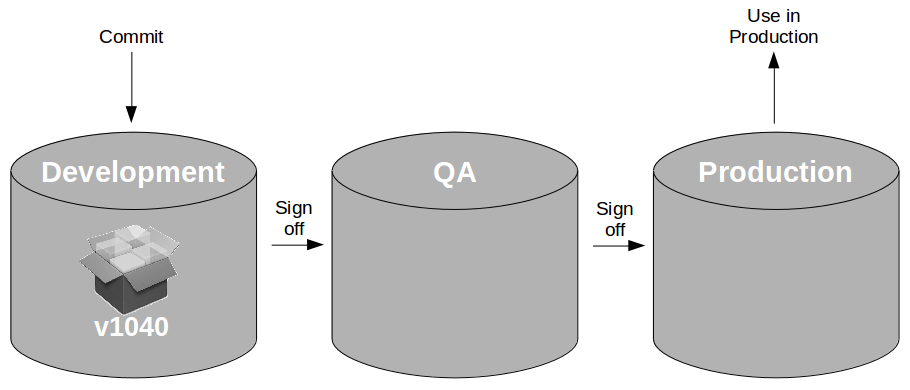
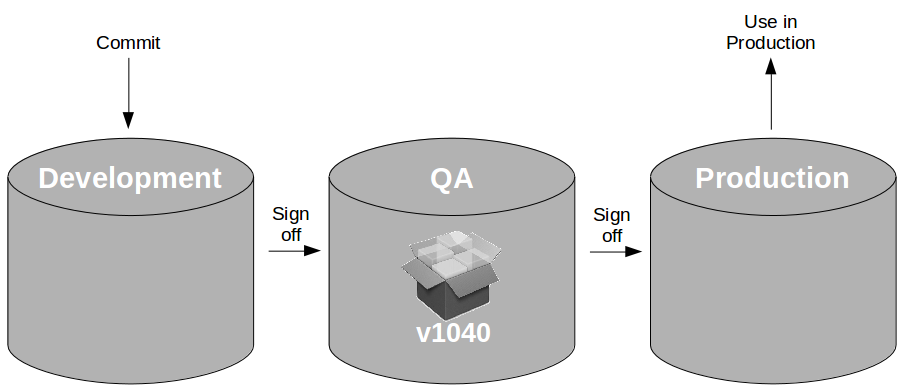
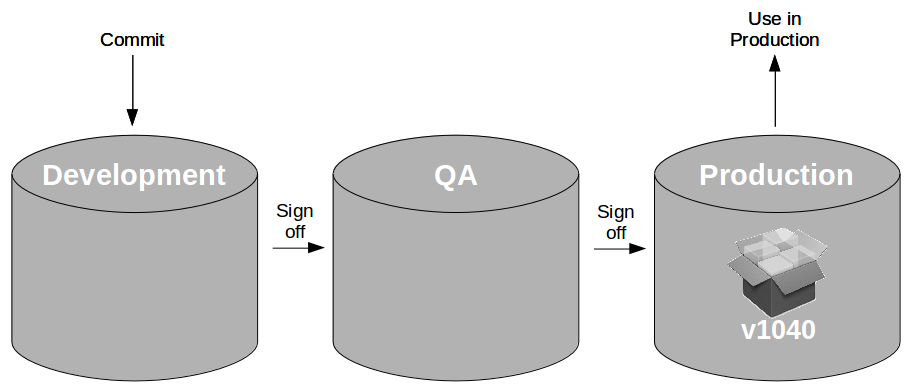
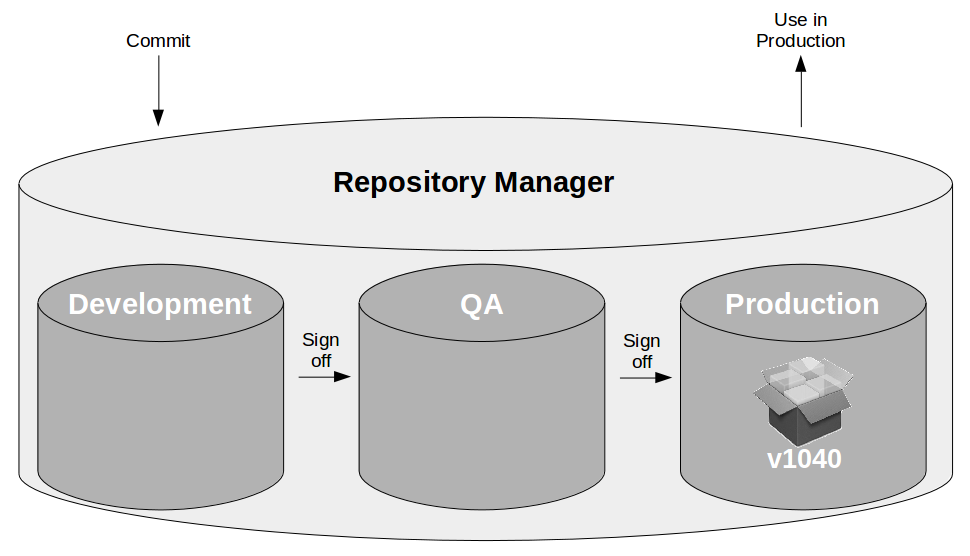
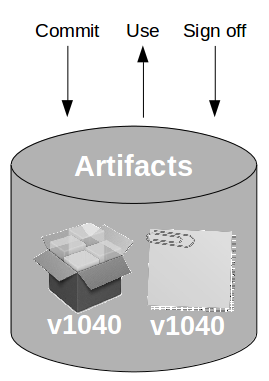
At the heart of Continuous Delivery is the Deployment Pipeline pattern, which extends the development practice of Continuous Integration to establish an automated workflow of build, test, and release activities from checkin to production. Any change to code, configuration, infrastructure, reference data, or database schema triggers a pipeline run, which packages a new artifact version and stores it in the artifact repository. That artifact is then subjected to a series of automated and exploratory tests to evaluate its production readiness, progressing to the next stage on success or halting upon failure. The result of this rigorous and repeatable testing process is a release candidate that meets well-defined quality standards and instils confidence prior to production release.
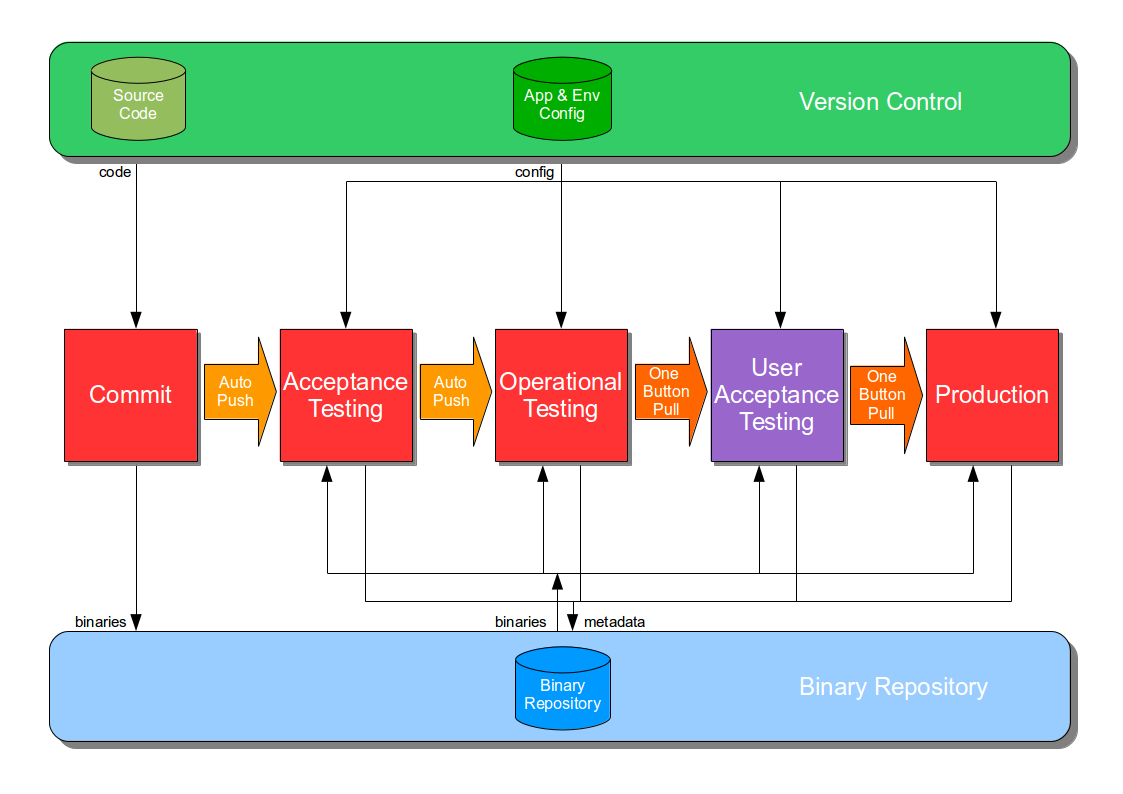
Automating a deployment pipeline offers the following advantages:
- Automated configuration – application behaviour is modified consistently, reducing runtime errors
- Automated infrastructure – operating systems, middleware, and networks are automatically provisioned, preventing environmental errors
- Automated testing – acceptance and performance tests are automated with production reference data, providing fast feedback
- Automated database management – database scripts are versioned and applied from development to production, uncovering errors sooner
- Automated operations – releases are a push button process for authenticated users, reducing human error
- Automated monitoring – operational checks are automated, increasing confidence in the production environment
- Automated rollback – rollback uses the standard release mechanism, ensuring a reliable rollback on error
- Automated statistics – lead time data is easily collected, enabling visualisation of metrics such as cycle time
- Automated audit – all actions are recorded, forming a timely and accurate audit trail
A deployment pipeline tightens feedback loops, reduces error rates, and automates repetitive tasks so that humans are freed up to work on higher-value activities – testers can perform exploratory testing, database administrators can plan for capacity, and systems administrators can create business-facing monitoring checks to learn from customers. Automated configuration and automated infrastructure provisioning are particularly important as they allow operational changes to be developed, tested, and released using exactly the same process as functional changes.
There is a wide range of practices that can be applied throughout a deployment pipeline, including the following
| Practice |
Description |
Advantage |
| Build Artifacts Once |
Build immutable artifacts on commit |
Prevents compiler errors post-development |
| Stop The Line |
Prioritise a releaseable codebase over new features |
Improves flow of features to production on predictable timelines |
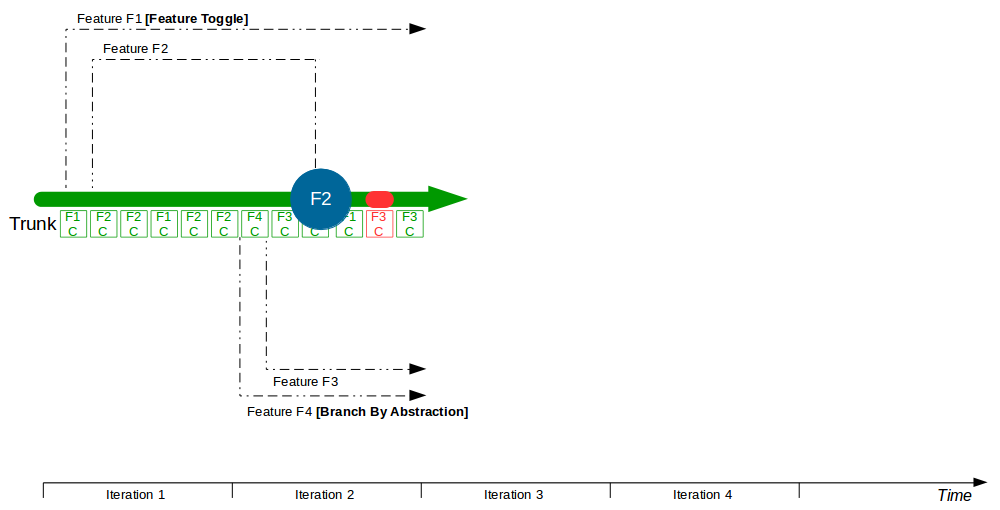
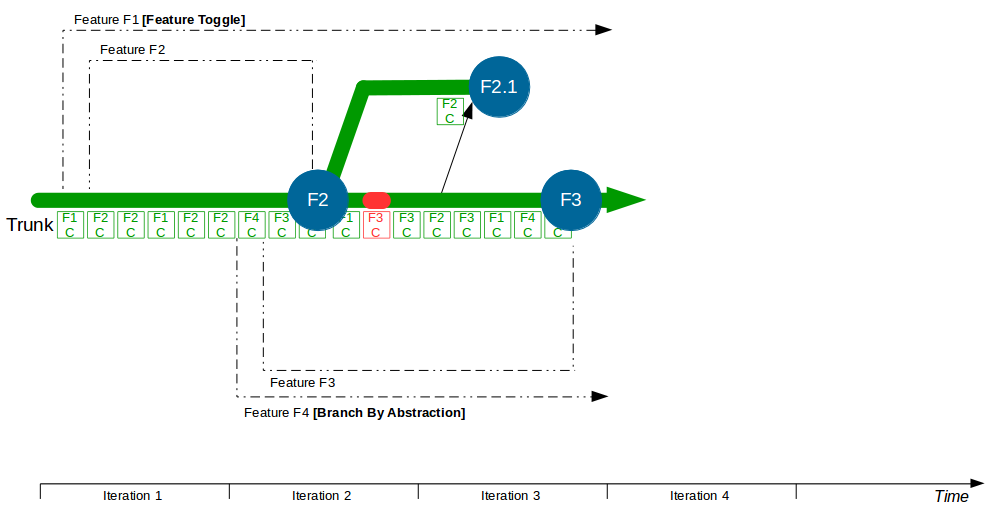
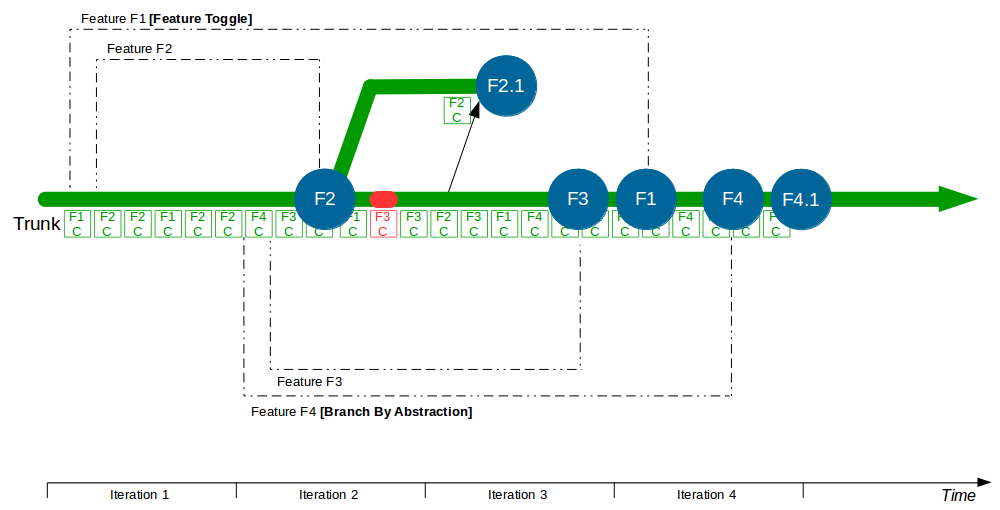
| Trunk Based Development |
Commit changes directly to trunk |
Minimises merge costs and encourages good design practices |
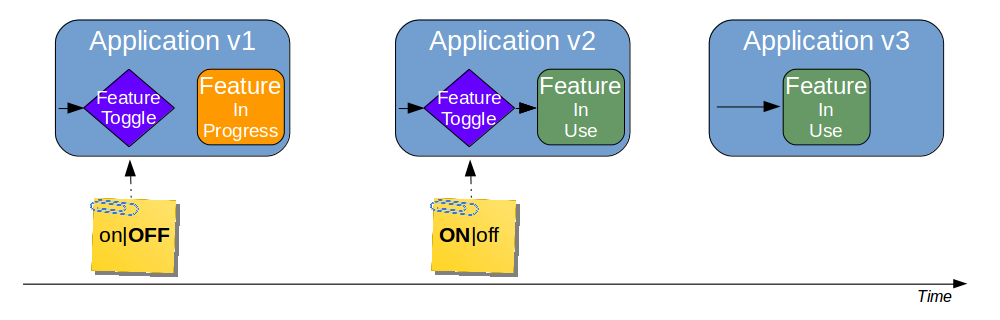
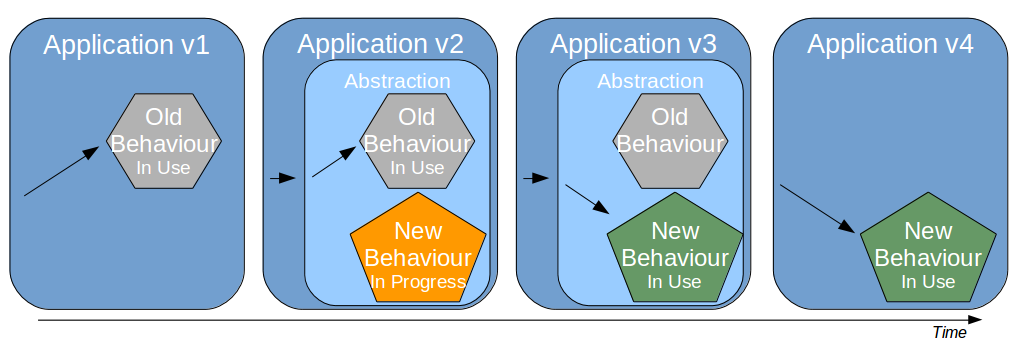
| Feature Toggle |
Turn features on/off at runtime |
Reduces operational fragility and permits fine-grained feature launches |
| Atomic Tests |
Write automated tests that own all their data |
Enables tests to be parallelised and speed up developer feedback |
| Consumer Driven Contracts |
Test consumer/provider interactions as unit tests |
Shrinks integration costs and constantly tests conversational integrity |
| Separate Schema And Data |
Split schema and reference data origins |
Improves reliability of database changes and data quality |
| Expand/Contract |
Stagger constructive and destructive schema changes |
Enables database migrations to occur with zero downtime |
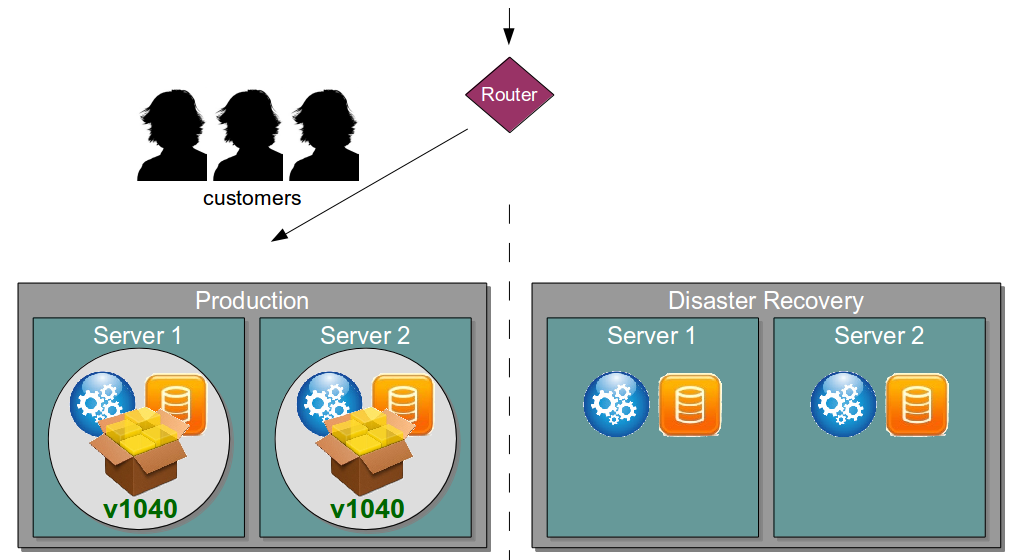
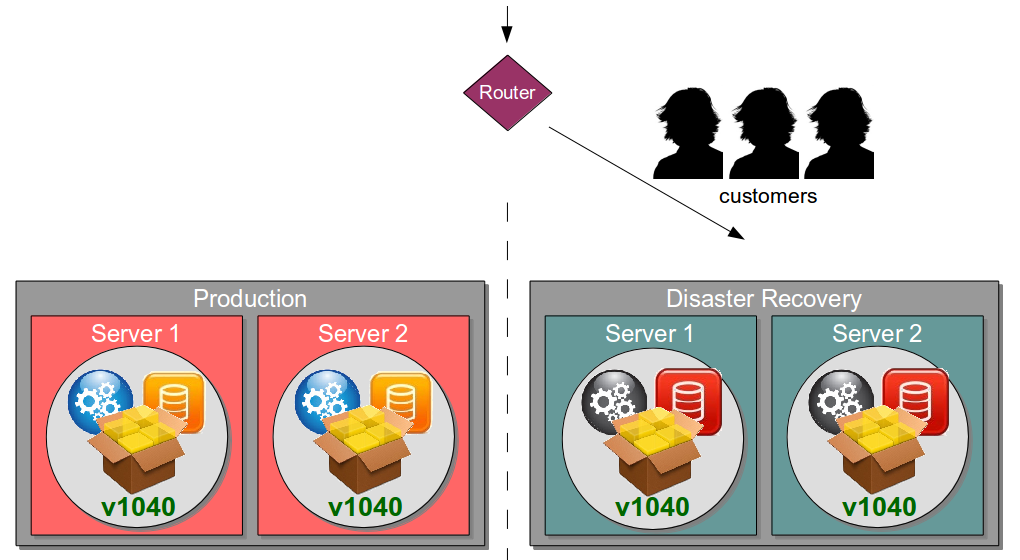
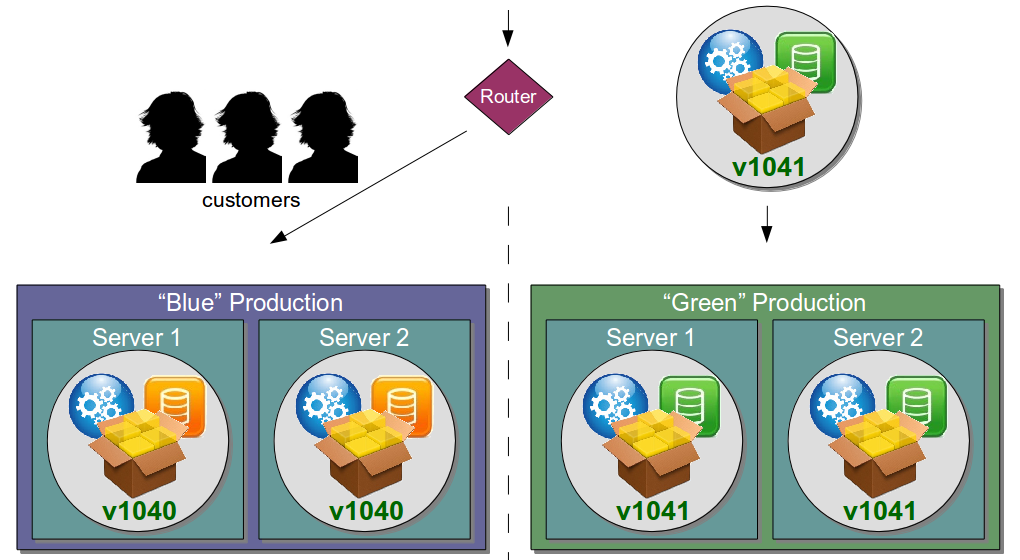
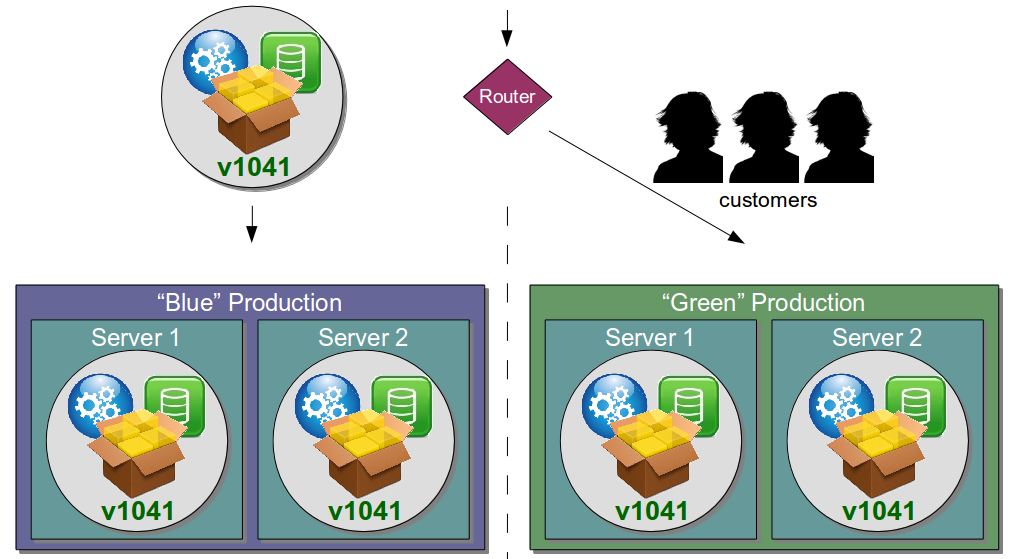
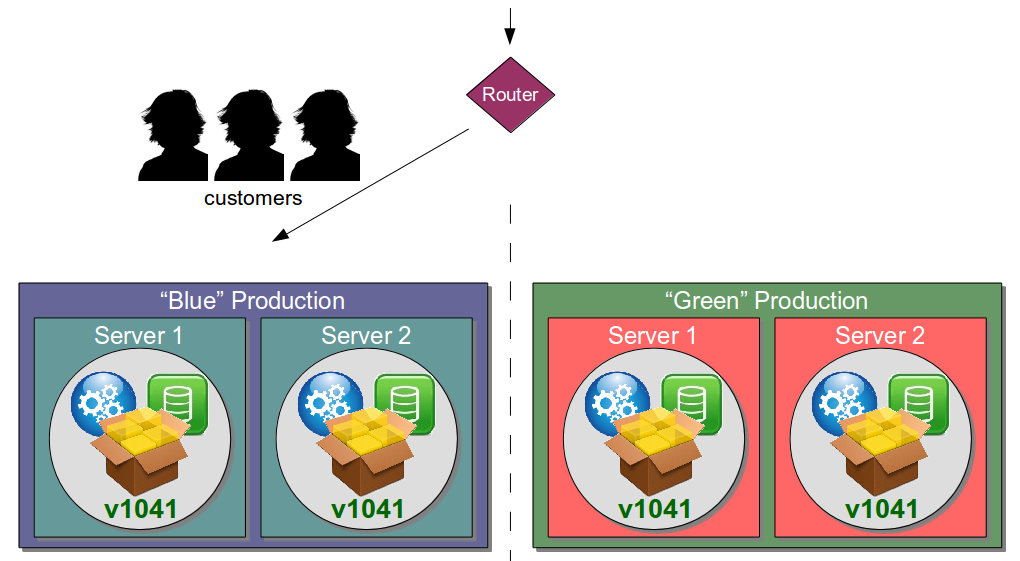
| Blue Green Releases |
Perform new release into standby production servers |
Allows production server upgrades to occur with zero downtime |
| Canary Releasing |
Perform new release one server at a time |
Reduces risk of production upgrade error affecting customers |
Together these practices enable an organisation to rapidly develop, test, and release high quality software with a low error rate and zero downtime in production.
Batch Size Reduction
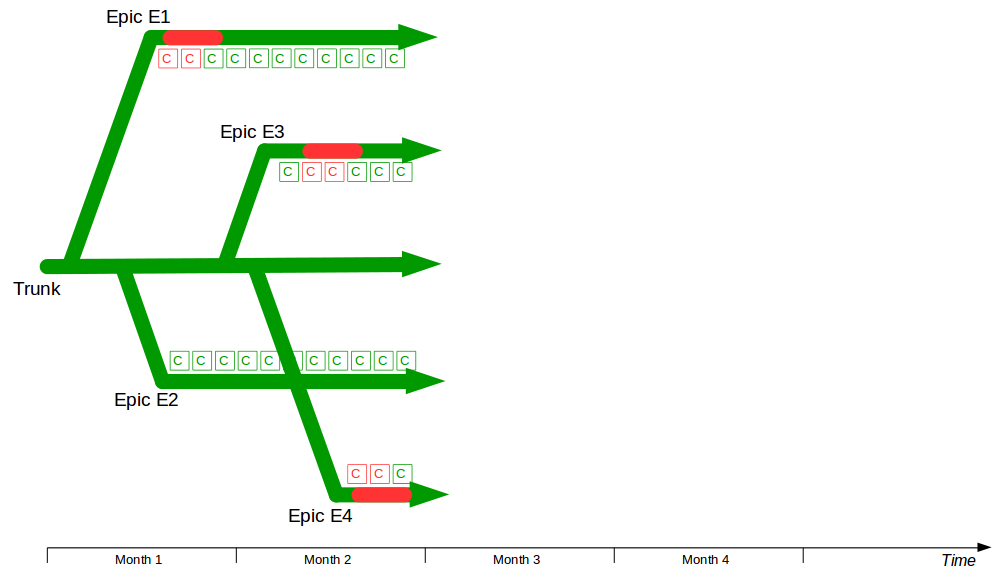
Once a deployment pipeline is established it can be used to reduce batch size and release smaller changesets into production more frequently, resulting in a lower cycle time that delivers value-add faster at a lower level of risk. In the earlier example, assume the product increment with an estimated value of £70,000 is comprised of 4 features and the estimated failure probability is 1 in 2 (50%).
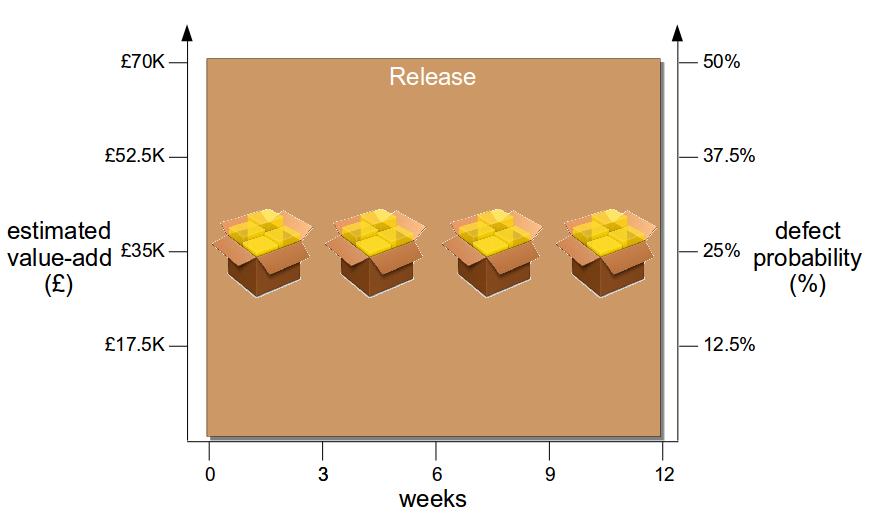
Now assume the organisation has adopted Continuous Delivery to the extent it can release 1 feature at a time every 3 weeks via its deployment pipeline. A smaller batch size reduces changeset complexity, so more accurate estimates of value-add and risk per release become possible – and as product development is heterogeneous different features offer different amounts of value-add and risk, meaning releases can be ordered by relative value-add and risk.
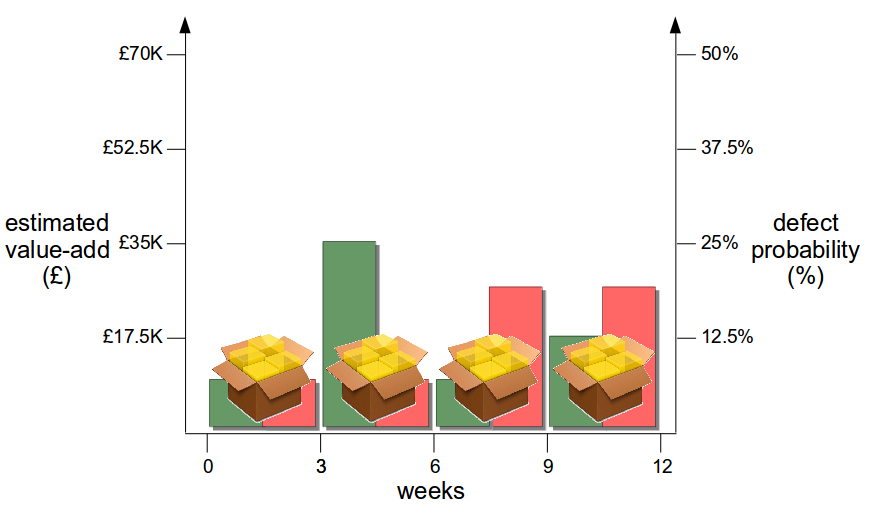
This breakdown of value-add and risk shows that Feature 2 should be released prior to Feature 1, as it will realise 50% of the original value-add in 25% of the original timeline with only a 6.25% failure probability. Exploratory testing of Features 3 and 4 can be increased to mitigate their heightened risk, and if a production defect does occur the smaller changeset size and lower cycle time means defects can be identified and resolved at a much lower cost.
Combining small production releases with a well-defined authorisation model and automated audit trail means a deployment pipeline can be a definitive compliance tool entirely compatible with ITIL. The ITIL v3 Service Transition definition of a Standard Change as a pre-authorised, low risk, and common change matches the Continuous Delivery concept of frequently releasing small changesets into production. The change management approval process can be implemented as an automated button push for authorised users, and in the rare situation where a small production release is not possible a more involved Normal Change procedure can be followed.
Organisational Change
While a wide range of tools are available to build a deployment pipeline – such as Zookeeper for configuration management, Puppet/AWS/Docker for infrastructure provisioning, Capistrano for deployments, and Graphite/Logstash for traceability – tool selection will not have a significant impact upon the success or failure of a Continuous Delivery programme. The central challenge of Continuous Delivery is undoubtedly organisational change, as many organisations consist of siloed teams with their own local incentives and priorities. Business stakeholders handover requirements to Development, who handover release candidates to Testing, who handover releases to Operations, who handover features to customers – and those handovers introduce significant delays into the value stream that will comprise the majority of cycle time.
In the earlier example, the 12 week cycle time would likely contain delays caused by issues such as test hardware procurement, database administrator unavailability, and change advisory board scheduling. Such delays are entirely unrelated to technology choices and must be addressed via organisational change.
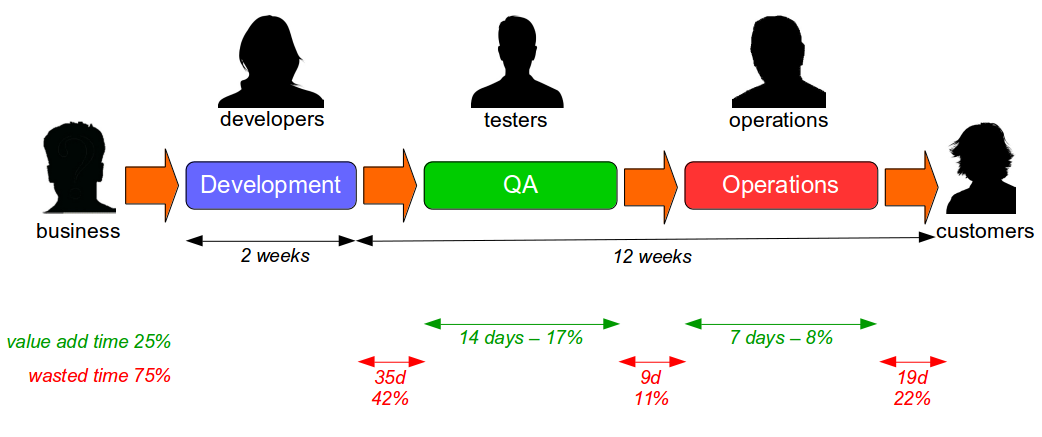
If an organisation is to successfully adopt Continuous Delivery it must harmonise its communication pathways with Conway’s Law, which postulates a correlation between organisational and system architecture now accepted as canon within IT:
“Any organisation that designs a system (defined broadly) will produce a design whose structure is a copy of the organisation’s communication structure” Mel Conway
Conway’s Law explains why siloed teams within the same value stream inevitably use their own tooling and processes – such as developers using a different database migrator to database administrators – and strongly implies that the most effective method of software delivery is cross-functional product teams with complete authority and responsibility for their deployment pipeline.
If an organisation wants to reap the rewards of Continuous Delivery it must change itself, and as Linda Rising and Mary Lynn Manns have observed “change is best introduced bottom-up with support at appropriate points from management“. Executives must communicate well-defined business outcomes, encourage innovators and early adopters, and help their staff with the transition. As Edgar Schein suggests in his book “Organisational Culture and Leadership” change often triggers learning anxiety and survival anxiety in individuals, so for people to commit to Continuous Delivery they must feel part of a culture of continuous improvement in a blame-free environment.
The DevOps philosophy conceived by Patrick Debois in 2009 is a popular method of fostering a culture of collaboration, and its emphasis upon Development and Operations working together on feature development and operability while sharing incentives can be a powerful force for change. However, as Dave Farley has observed “DevOps rarely says enough about the goal of delivering valuable software” and misinterpretations of its collaboration philosophy such as the DevOps Team antipattern are common.
While a deployment pipeline cannot directly reduce cycle time, it can indirectly contribute by acting as a central communication tool that facilitates organisational change. Radiating lead times and real-time customer monitoring from the deployment pipeline will show people the direct correlation between value stream bottlenecks and loss of customer revenue, and as a result people will better understand how change will benefit the entire organisation. This means organisational change for Continuous Delivery has an implicit dependence upon automation that can be summarised as follows:
Continuous Delivery is 10% automation and 90% organisational change – but don’t try it without that 10%
Dual Value Streams
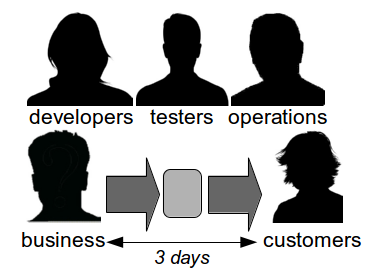
While Continuous Delivery appears to be a daunting prospect many organisations already contain evidence of their potential for success, as they have two different value streams – a Feature Value Stream of siloed teams that will take weeks or months, and a Fix Value Stream of natural collaboration that will take days.
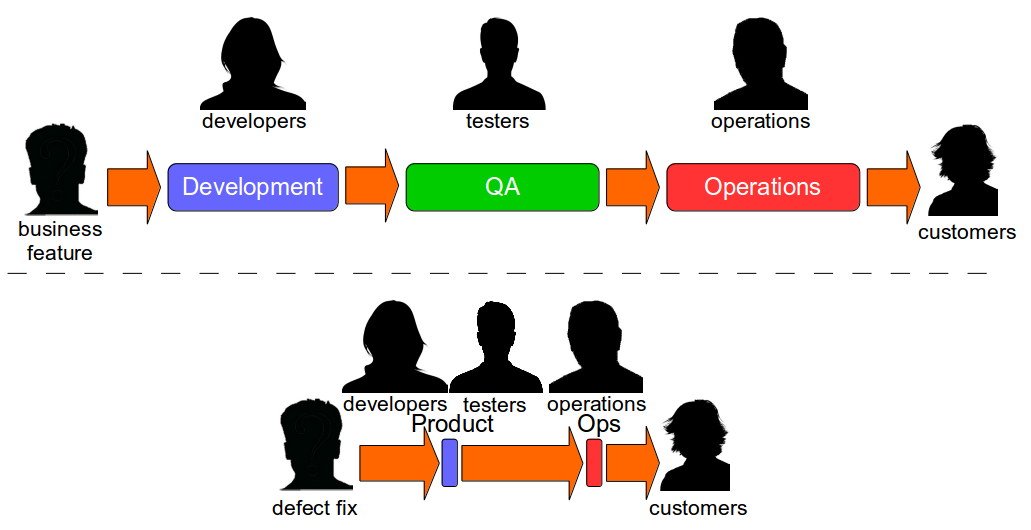
The reason Fix Value Streams have a much lower cycle time than Feature Value Streams is defect fixes are more easily assigned an estimated Cost Of Delay that can be communicated throughout an organisation. When people know a defect has caused a sunk cost and an opportunity cost is pending there is a shared sense of urgency that encourages collaboration and a truncated value stream. This is a leading indicator of organisational potential for Continuous Delivery, and highlights how inappropriate the project paradigm is for product development. When an organisation works on features in smaller batches it can use Cost Of Delay to better prioritise work and improve flow through its Continuous Delivery pipeline.
Conclusion
It is time for businesses to recognise the strategic value of an IT capability that can rapidly innovate and respond to customer feedback in existing and emerging markets. Continuous Delivery enables an organisation to significantly reduce its time to market for new features, resulting in improved quality and increased product revenues.
Automating a deployment pipeline and accomplishing organisational change for Continuous Delivery is a long-term investment. Jez Humble at al say “the key is to find ways to make small, incremental changes that deliver improved customer outcomes“, and Dave Farley says “break down barriers, increase automation, increase collaboration and iterate“. Regardless of approach, a successful adoption of Continuous Delivery will provide an organisation with an enormous advantage over competitors. If an organisation does not adopt Continuous Delivery, it will eventually lose out to a competitor that can deliver faster, learn from customers faster, and make money faster. You can ignore the economics, but the economics won’t ignore you…
Further Reading
- Continuous Delivery by Dave Farley and Jez Humble
- Lean Enterprise by Jez Humble, Joanne Molesky, and Barry O’Reilly
- Implementing Lean Software Development by Mary and Tom Poppendieck
- Fearless Change by Linda Rising and Mary Lynn Mann
- Organisational Culture and Leadership by Edgar Schein
- Principles Of Product Development Flow by Don Reinertsen