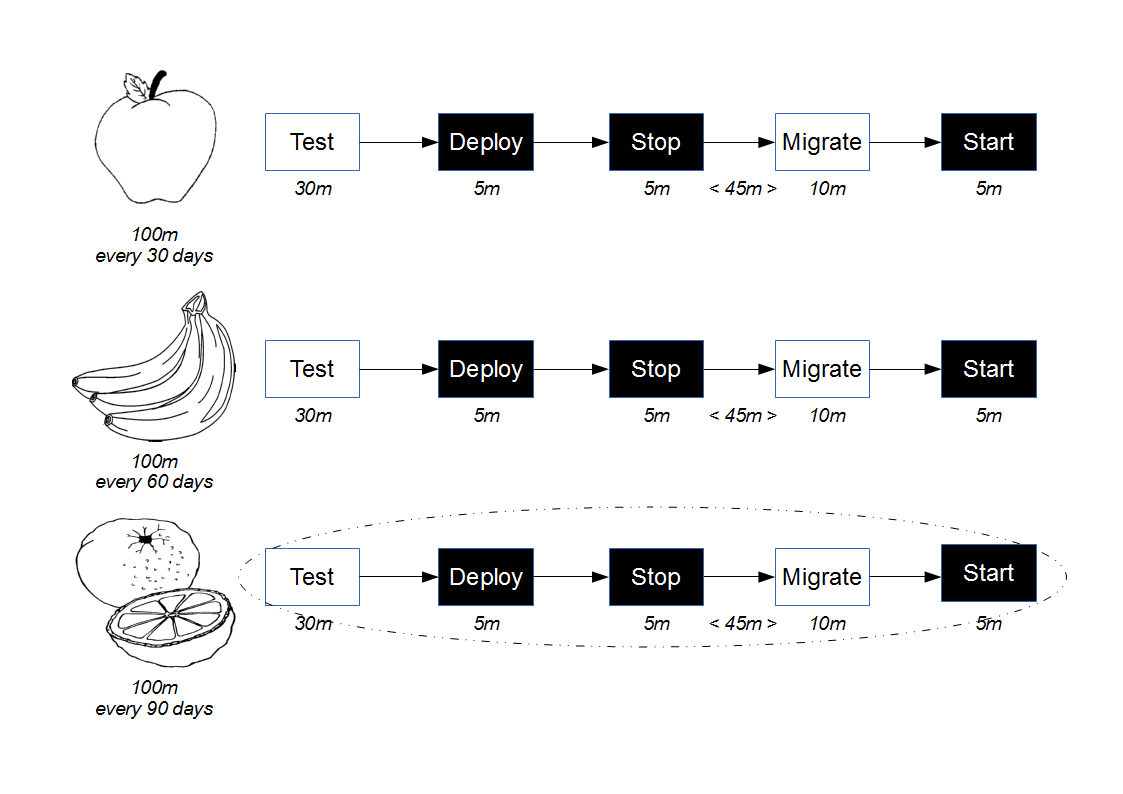
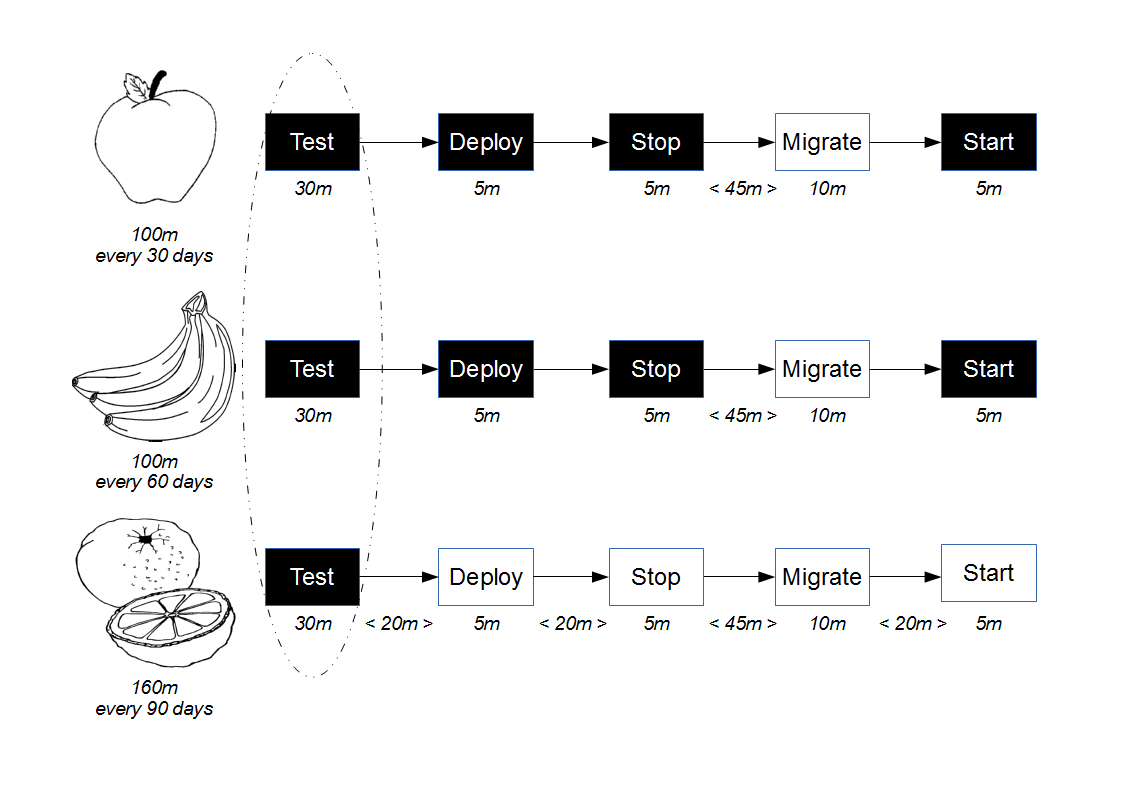
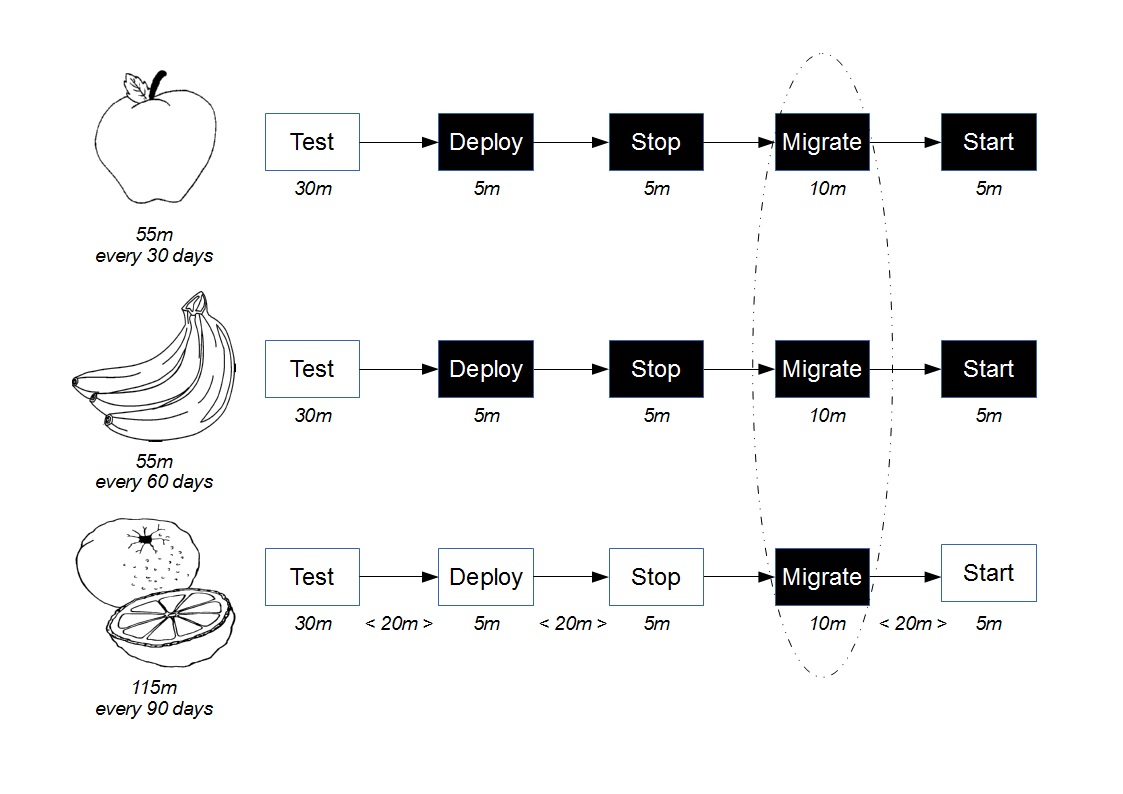
Proxy Consumer Driven Contracts simulate provider-side testing
When Continuous Delivery is applied to an estate of interdependent applications we want to release as frequently as possible to minimise batch size and lead times, and Consumer Driven Contracts is an effective build-time method of verifying consumer-provider interactions. However, Consumer Driven Contracts assumes the provider will readily share responsibility for conversation integrity with the consumer, and that can be difficult to accomplish if the provider has different practices and/or is a third-party organisation. How can Consumer Driven Contracts be adapted to an environment in which the provider cannot or will not engage in joint risk mitigation?
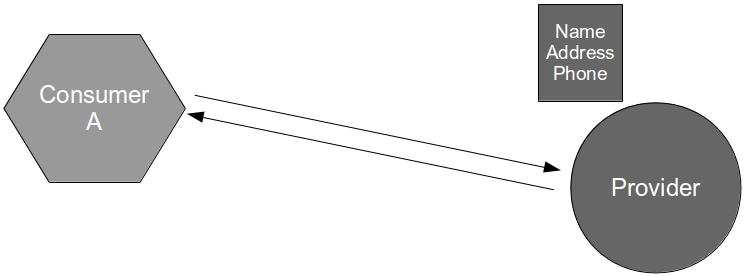
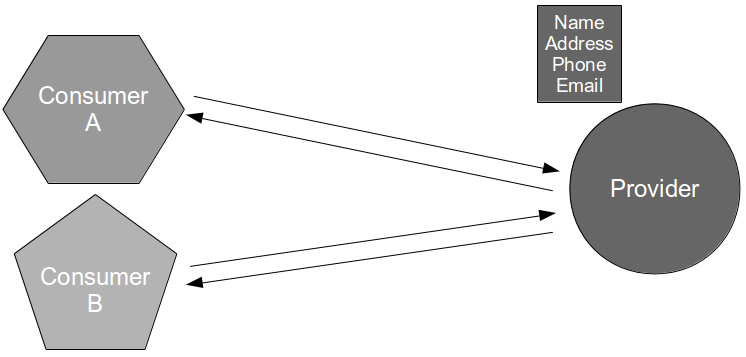
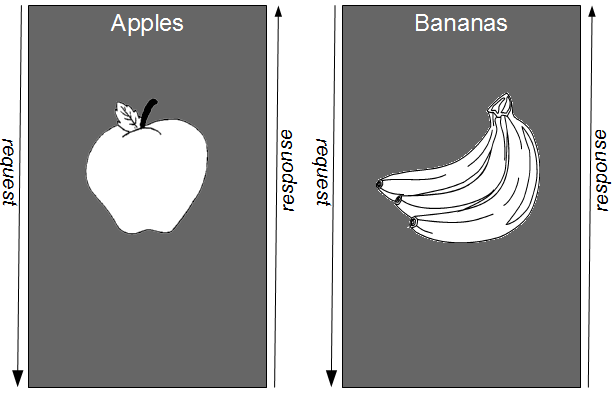
For example, consider an organisation in which the applications Consumer A and Consumer B are dependent upon a customer details capability offered by a third-party Provider application. The Provider Contract is communicated by the third-party organisation as an API document, and it is used by Consumer A and Consumer B to consume name/address and name/address/email respectively. Consumer Contracts are made available to the provider for testing, but as the third-party organisation has more lucrative customers and a slower release cycle it is is unwilling to engage in Consumer Driven Contracts.
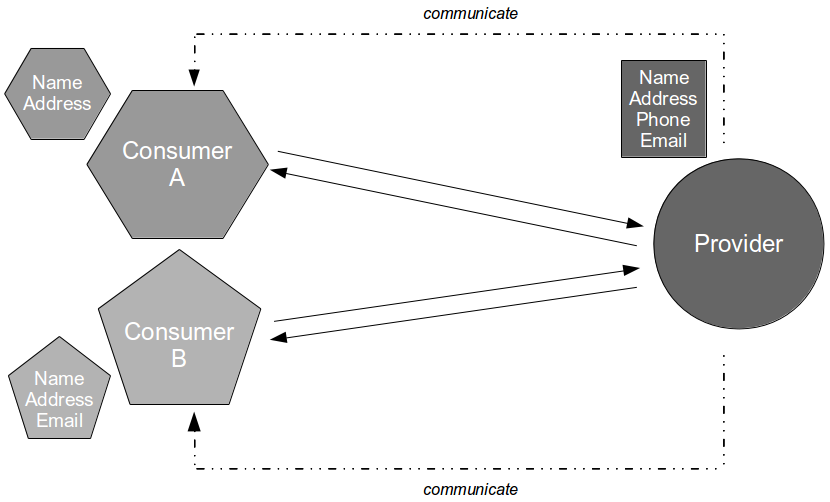
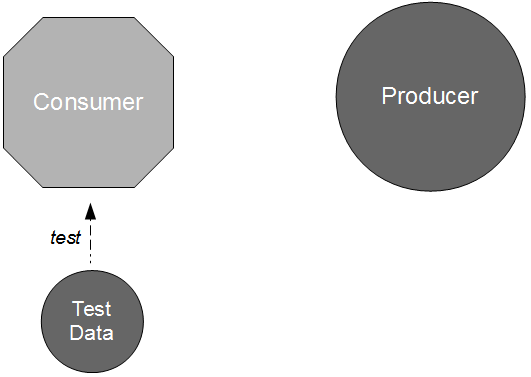
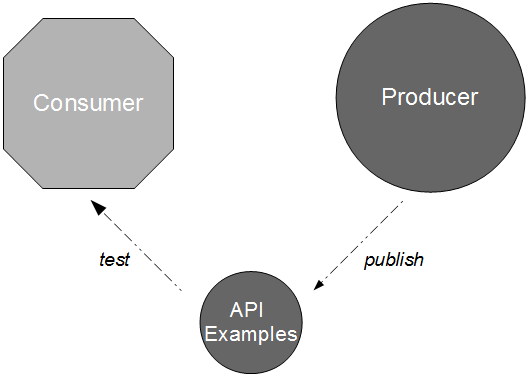
In this situation a new Provider release could cause a runtime communications failure with Consumer A and/or Consumer B with little or no warning. It is likely that some form of consumer-side integration testing will have to be adopted as a risk reduction strategy, unless the provider role within Consumer Driven Contracts can be simulated.
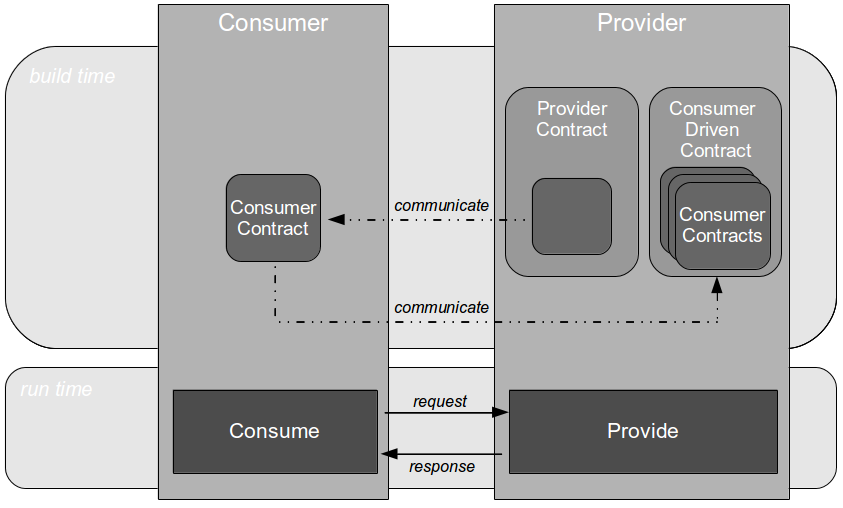
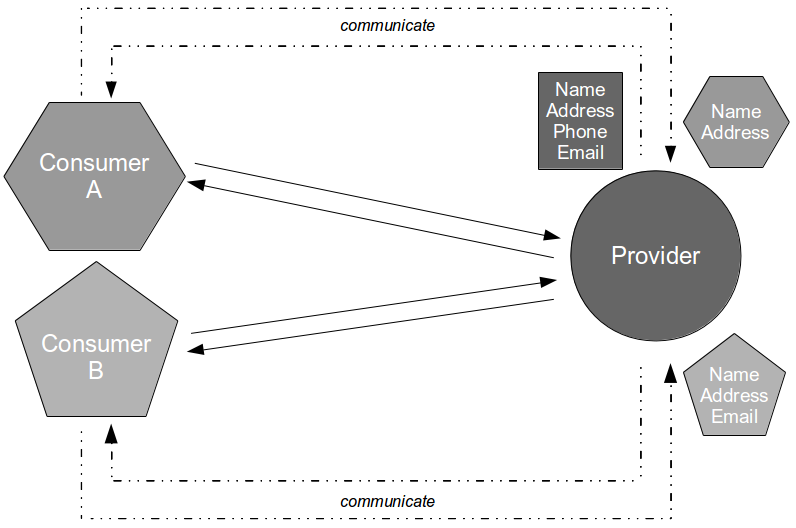
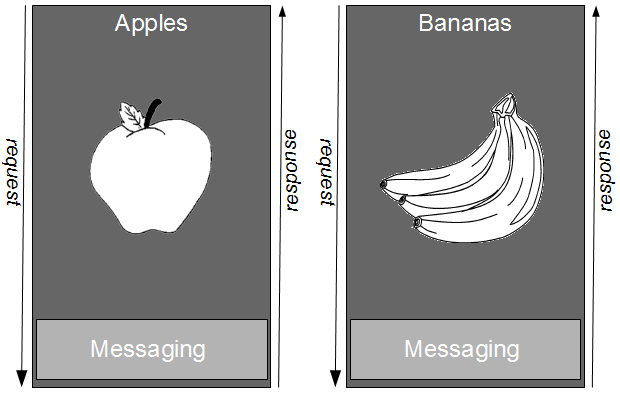
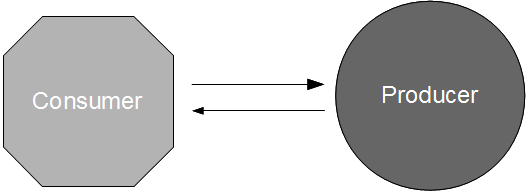
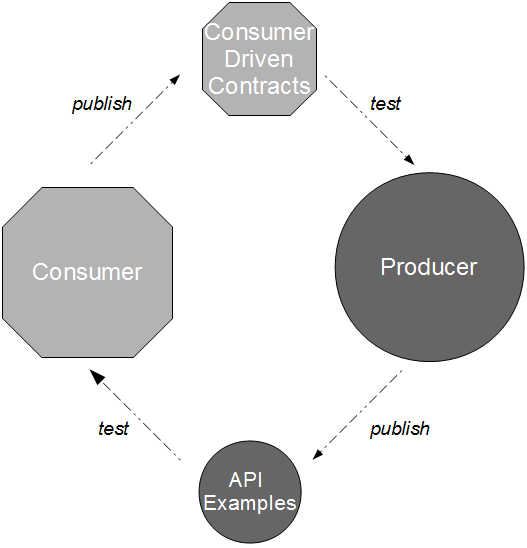
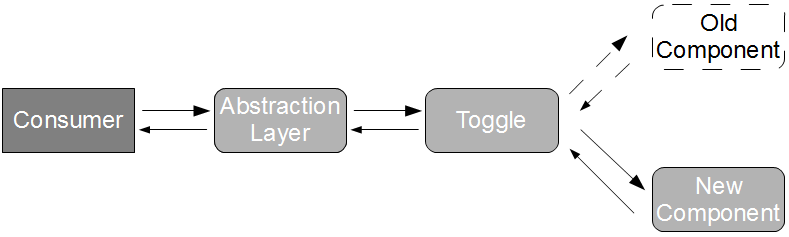
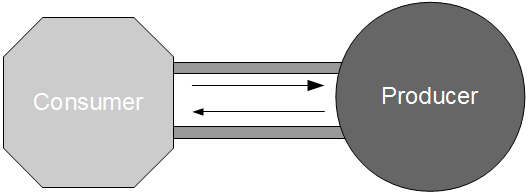
In Proxy Consumer Driven Contracts a provider proxy is created that assumes responsibility for testing the Consumer Driven Contracts as if it was the provider itself. Consumer A and Consumer B supply their Consumer Contracts to a Provider Proxy, which acts in a provider role.
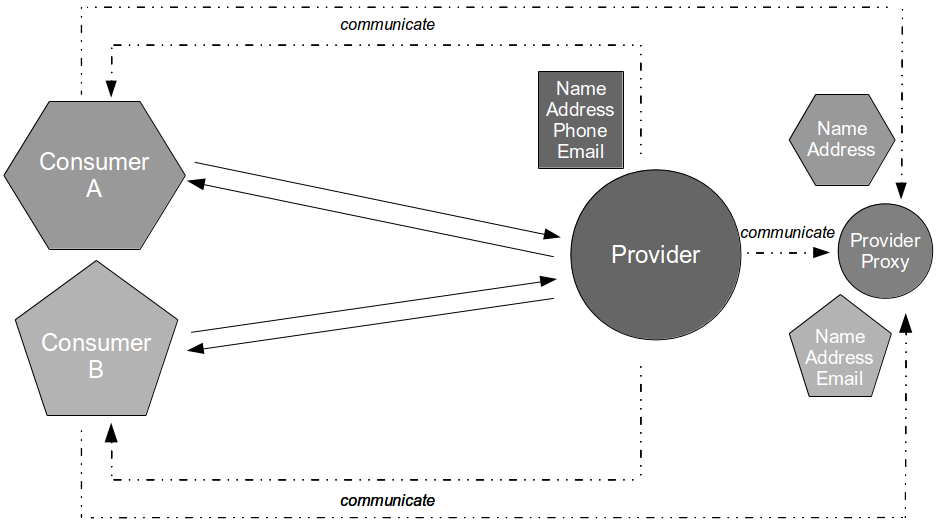
When a new Provider release is announced by the third-party organisation the updated API document is stored within the Provider Proxy source tree. This triggers a Provider Proxy commit build that will transform the human-readable Provider Contract into a machine-readable equivalent, and use it to validate the Consumer Driven Contracts previously supplied by Consumer A and Consumer B. This means incompatibilities can be detected merely seconds after new Provider documentation is supplied by the third-party organisation.
Proxy Consumer Driven Contracts incur a greater maintenance cost than Consumer Driven Contracts, but if the provider cannot or will not become involved in risk reduction then a simulation of provider-side unit testing should be preferable to a lengthy period of consumer-side integration testing.