Promoting artifacts between repositories is a poor man’s metadata
Note: this antipattern used to be known as Mutable Binary Location
A Continuous Delivery pipeline is an automated representation of the value stream of an organisation, and rules are often codified in a pipeline to reflect the real-world journey of a product increment. This means artifact status as well as artifact content must be tracked as an artifact progresses towards production.
One way of implementing this requirement is to establish multiple artifact repositories, and promote artifacts through those repositories as they successfully pass different pipeline stages. As an artifact enters a new repository it becomes accessible to later stages of the pipeline and inaccessible to earlier stages.
For example, consider an organisation with a single QA environment and multiple repositories used to house in-progress artifacts. When an artifact is committed and undergoes automated testing it resides within the development repository.
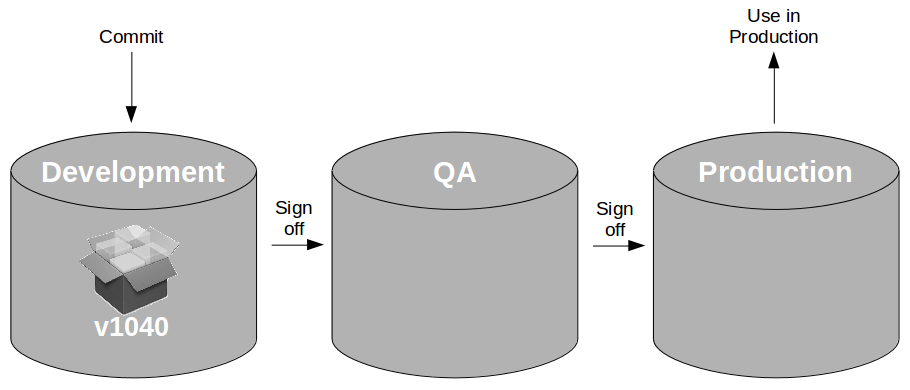
When that artifact passes automated testing it is signed off for QA, which will trigger a move of that artifact from the development repository to the QA repository. It now becomes available for release into the QA environment.
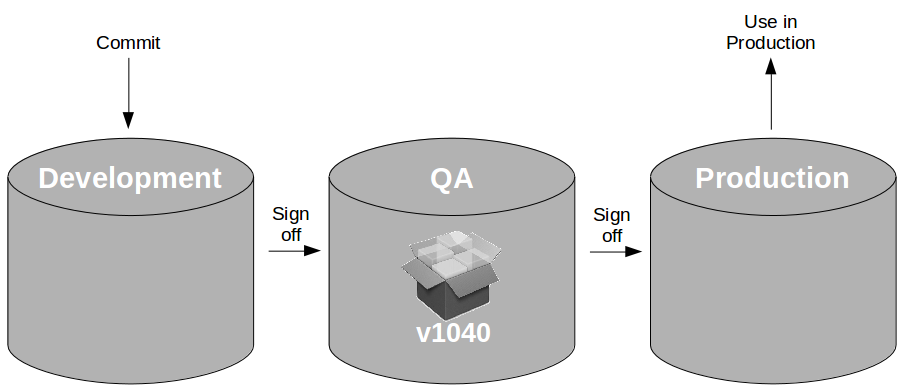
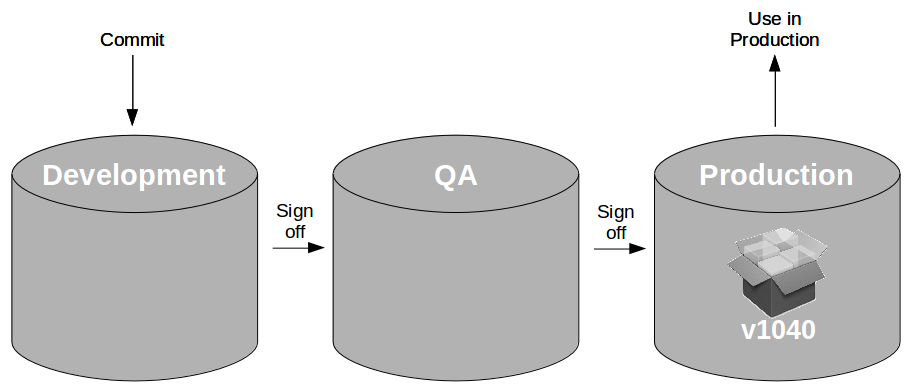
When that artifact is pulled into the QA environment and successfully passes exploratory testing it is signed off for production by a tester. The artifact will be moved from the QA repository to the production repository, enabling a production release at a later date.
A variant of this strategy is for multiple artifact repositories to be managed by a single repository manager, such as Artifactory or Nexus.
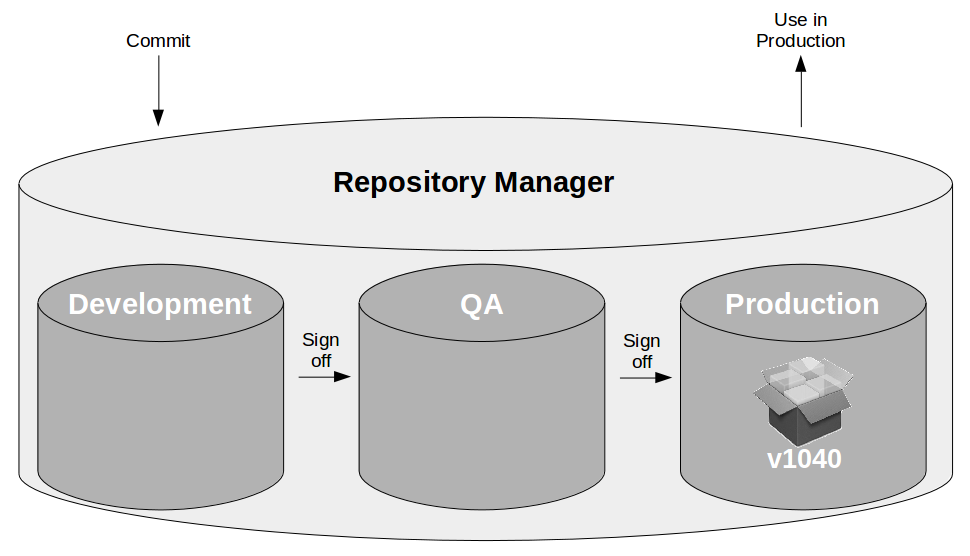
This strategy fulfils the basic need of restricting which artifacts can be pulled into pre-production and production environments, but its reliance upon repository tooling to represent artifact status introduces a number of problems:
- Reduced feedback – an unknown artifact can only be reported as not found, yet it could be an invalid version, an artifact in an earlier stage, or a failed artifact
- Orchestrator complexity – the pipeline runner has to manage multiple repositories, knowing which repository to use for which environment
- Inflexible architecture – if an environment is added to or removed from the value stream the toolchain will have to change
- Lack of metrics – pipeline activity data is limited to vendor-specific repository data, making it difficult to track wait times and cycle times
A more flexible approach better aligned with Continuous Delivery is to establish artifact status as a first-class concept in the pipeline and introduce per-binary metadata support.
When a single repository is used, all artifacts reside in the same location alongside their versioned metadata, which provides a definitive record of artifact activity throughout the pipeline. This means unknown artifacts can easily be identified, the complexity of the pipeline orchestrator can be reduced, and any value stream design can be supported over time with no changes to the repository itself.
Furthermore, as the collection of artifact metadata stored in the repository indicates which artifact passed/failed which environment at any given point in time, it becomes trivial to pipeline dashboards that can display pending releases, application cycle times, and where delays are occurring in the value stream. This is a crucial enabler of organisational change for Continuous Delivery, as it indicates where bottlenecks are occurring in the value stream – likely between people working in separate teams in separate silos.